A B2B buyer in 2026 no longer types "best CRM" into Google and works through ten blue links. She opens ChatGPT, describes her stack in three sentences, and accepts the synthesized recommendation it returns. By the time her sales team picks up the phone, the shortlist is set; and if your brand wasn't woven into the model's answer, you were never in the running.
This isn't a hypothetical shift. Industry projections indicate that traditional organic search engine volume will decline by 25% by late 2026 as user intent moves decisively toward conversational AI interfaces. 73% of B2B procurement managers now actively use generative AI search platforms - ChatGPT, Claude, and Perplexity - during initial vendor discovery, and 51% of enterprise buyers initiate research directly with a chatbot rather than a search engine.
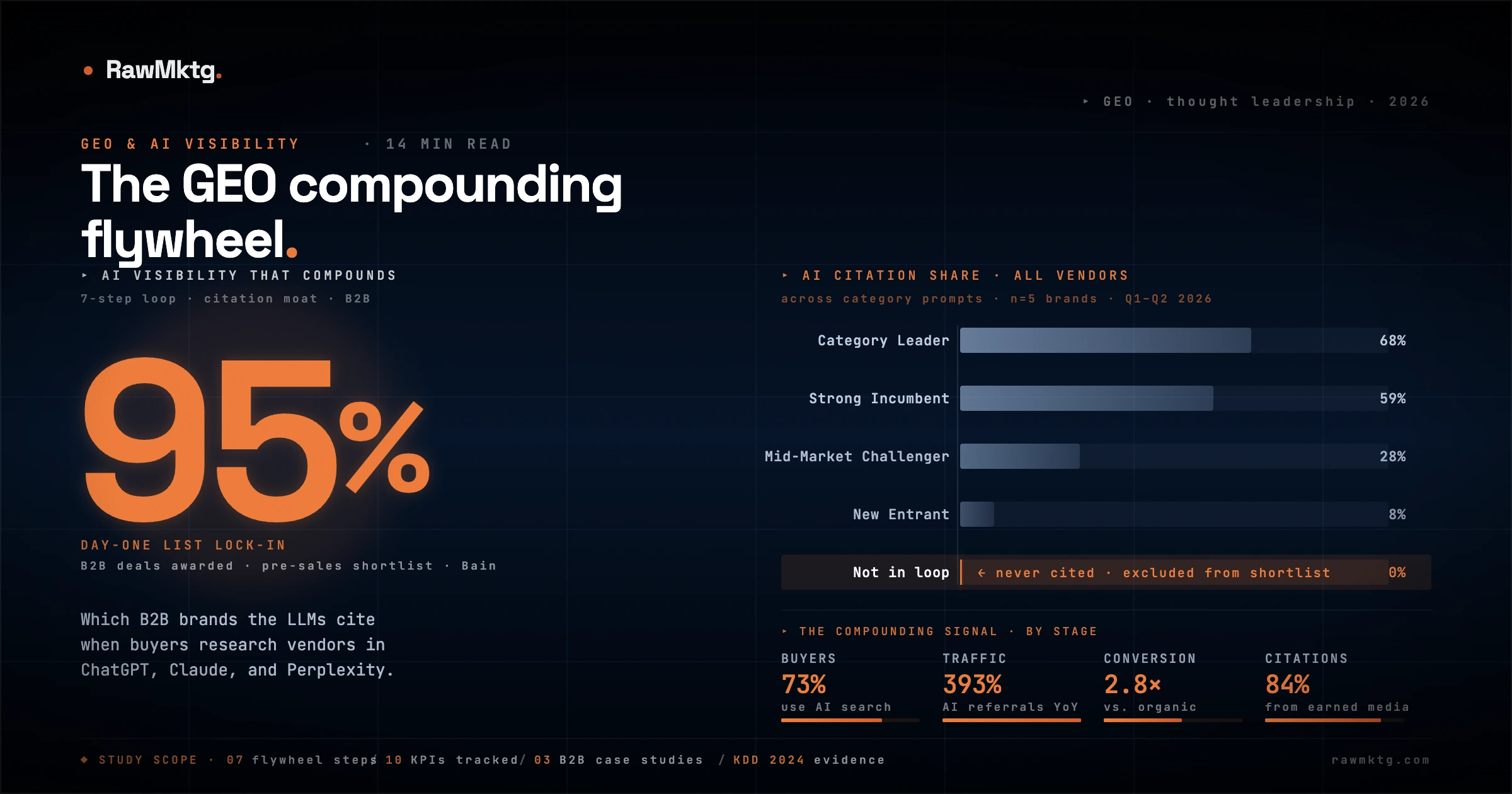
The reason this matters more than any previous channel shift is the structure of B2B buying itself. Bain's Buyer Experience Report shows that 95% of B2B purchase decisions are awarded to a vendor already on the buyer's "Day One List" - the consideration shortlist established before any sales outreach occurs. That shortlist used to be built from page-one Google results. Today it's synthesized inside a private chat, and if your brand isn't part of that synthesis, you are not just losing the click; you are being excluded from the deal entirely.
The economic profile of this new traffic makes the urgency sharper still. Adobe Analytics observed a 393% year-over-year surge in generative-AI referral traffic in early 2026, and these AI-referred visitors converted at more than twice the rate of standard search traffic. Less volume, much higher intent. The conclusion for any CMO, founder, or investor is uncomfortable but clear: capital must move from ranking-for-keywords to being-recommended-by-models. That discipline is Generative Engine Optimization (GEO), and the most important property of GEO is that, done right, it compounds.
01How does the GEO compounding flywheel work?
The loop has seven steps, and most teams trying to "do GEO" fail because they execute one or two of them in isolation. The compounding effect only kicks in when the full cycle is closed.
Walk through it once and the architecture becomes clear:
01 · Build
The loop starts with the creation of entity-dense, citation-first digital assets that lead with the direct answer to a category query in the first 60-120 words. This is not the same as writing a "good blog post." It is structured knowledge engineering: clustering named entities - brands, people, studies, numbers - into passages that an LLM can lift, attribute, and cite without rewriting.
02 · Crawl
Built assets are useless until they are reachable. Robots.txt, XML sitemaps, and server architecture must explicitly grant access to search-retrieval crawlers, while strategically governing the training harvesters. The trap most teams fall into here is symmetric blocking - accidentally banning the very bots that produce citations.
03 · Train / Retrieve
Crawled content enters two parallel pipelines simultaneously. In the long run, pages are ingested into foundational model training runs, embedding your brand into the next generation of weights. In the short run, pages are indexed as high-dimensional vectors inside the RAG systems that ground real-time answers in live web data.
04 · Rate
At query time, the retrieval engine doesn't just match keywords. It runs dense and sparse searches in parallel, merges them with Reciprocal Rank Fusion, then re-ranks every candidate. Pages scoring below a strict confidence threshold are discarded outright to protect factual accuracy. Most legacy SEO content never gets past this gate.
05 · Recommend
Survivors are stripped of boilerplate. The model lifts the most relevant excerpts and synthesizes them into a single conversational response, choosing to cite the brand whose content offers the highest contextual alignment with the user's request. This is the moment the buyer sees your name - or doesn't.
06 · Validate
Before the model commits to recommending you, it cross-references its synthesis against independent external nodes in its knowledge graph. If your claim about being the leader in X cannot be corroborated by an authoritative third party - a trade publication, an industry registry, a major analyst - the citation gets dropped to protect the model from hallucination.
07 · Re-signal
This is the step that turns a process into a flywheel. Buyers click on the citation, run follow-up branded queries on Google, and visit your site. Those behavioral signals get recorded, the team updates the source pages with fresh statistics, and the freshness pings trigger immediate re-crawling, which expands your vector footprint, which makes you easier to retrieve in step 04 next time. The loop tightens on itself.
| Stage | Primary Technical Objective | Operational KPI | Strategic Focus |
|---|---|---|---|
| 01 · Build | Maximize informational density and entity relationships | Named-Entity Density / 100 words | Citation-first structural layout |
| 02 · Crawl | Frictionless indexing by real-time search bots | Crawl success rate in server logs | Explicit unblocking of search user-agents |
| 03 · Train/Retrieve | Position in model weights AND vector DBs | Vector index density for category terms | Continuous ingestion of high-value pages |
| 04 · Rate | Survive query transformations and RRF merging | Re-ranking confidence score | Hybrid dense-sparse compatibility |
| 05 · Recommend | Placement in the synthesized response | Answer Inclusion Rate | Direct, excerpt-ready phrasing |
| 06 · Validate | Align claims with trusted third-party nodes | High-authority off-site mentions | Editorial features and trade reviews |
| 07 · Re-signal | Refresh authority and capture post-click intent | Branded search growth + sitemap freshness | Update content every 60 days |
A wave of "GEO agencies" is selling listicle-spam optimized for AI crawlers. Don't buy it. Researchers warn that recursive training on AI-generated low-value content produces model collapse - degraded, homogenized outputs. To prevent that decay, AI labs are now actively tuning retrieval models to penalize synthetic, machine-targeted content. Shallow GEO content gets discarded at step 04. The only durable strategy is depth and original value for human readers, which conveniently produces the high-integrity data the models are designed to surface.
02How does AI retrieval actually decide what to cite?
To engineer for the flywheel, a CMO needs at least a working mental model of what happens at step 04. When a buyer types a prompt, the system does not search your website. It searches an index - a mathematical representation of the web compiled days, weeks, or months ago - and it does so through a multi-stage filter known as Retrieval-Augmented Generation (RAG). But RAG is not uniform: ChatGPT, Perplexity, and Gemini each apply different retrieval logic once your content enters their index.
Query Transformation: the prompt is not the search
Before anything is retrieved, the model rewrites the query. Three transformations dominate production RAG systems:
- Query Decomposition (Fan-out). "Compare product A with product B on pricing and integrations" becomes two parallel searches: one for A, one for B. Pages that only answer half of a comparative prompt lose both halves.
- Hypothetical Document Embeddings (HyDE). The LLM drafts an ideal answer, embeds that, and searches with it. Vector matching becomes answer-to-document instead of query-to-document. Pages written in the voice of a textbook answer get retrieved; pages written in the voice of a brochure don't.
- Reasoning-Then-Embedding (LREM). A short prompt like "best CRM under $100" gets expanded into "CRM software recommendations with explicit pricing tables, feature lists, and monthly costs currently under $100" before search begins.
Dense, sparse, and the RRF merge
Modern RAG runs two retrieval methods in parallel because each catches what the other misses. Dense search uses high-dimensional vector embeddings to find conceptually similar content. Sparse search (BM25) uses probabilistic keyword matching for SKUs, exact prices, and proper nouns. Their scores are on incompatible scales, so the system merges them with Reciprocal Rank Fusion:
The intuition is simple: RRF naturally rewards documents that rank highly in both lists, which is exactly the profile of content that has semantic depth and precise terminology. Your job, as a content team, is to write pages that win on both axes.
| Retrieval Mechanism | Underlying Algorithm | Strength | Weakness |
|---|---|---|---|
| Dense · Vector | Cosine similarity on embeddings | Concepts, synonyms, intent | Misses SKUs, exact prices |
| Sparse · BM25 | Probabilistic TF-IDF + length norm | Exact codes, pricing, brand names | Blind to conceptual synonyms |
| RRF · Hybrid | Reciprocal Rank Fusion | Combines depth + precision | Higher complexity and latency |
The re-ranker is the gatekeeper
Once the hybrid search has 50-100 candidate documents, a cross-encoder re-ranker scores every (query, document) pair jointly. Each candidate gets a relevance score between 0 and 1. Anything below approximately 0.75 is dropped. Survivors have their boilerplate stripped, relevant passages extracted, concatenated into a context block, and handed to the LLM for synthesis.
Your page either crosses the confidence threshold or it doesn't exist for that query. There is no second page of generative results.
03What does the Princeton GEO study actually prove?
The academic spine of GEO was laid down by Aggarwal et al. in their KDD 2024 paper "GEO: Generative Engine Optimization" - a collaboration between Princeton, Georgia Tech, IIT Delhi, and the Allen Institute for AI. The team built GEO-bench, a benchmark of 10,000 queries across eight domains, and tested whether specific content modifications actually moved citation rates.
They measured impact two ways: Position-Adjusted Word Count (PAWC), which weights how much of your text the model lifts and how prominently it places it, and Subjective Impression (SI), a qualitative score for how prominently the source is highlighted to the reader. Then they ran nine optimization tactics through the gauntlet. Five worked. Four failed.
| Tactic Tested | Result | Why It Behaves This Way |
|---|---|---|
| Statistics Addition | + citation lift | Numbers are easier to extract and cite than soft narrative |
| Cite Sources | + citation lift | Models read inline citations as trust signals |
| Quotation Addition | + citation lift | Expert quotes provide unique, high-information content |
| Fluency Optimization | + citation lift | Matches the high-quality writing overrepresented in training data |
| Authoritative Voice | + citation lift | Confident phrasing raises re-ranker confidence scores |
| Keyword Stuffing | no benefit / negative | Lexical repetition is invisible in vector space; filtered by re-ranker |
| Easy-to-Understand | no benefit / negative | Dumbing down strips the terminology used for semantic matching |
| Content Padding | no benefit / negative | Lowers info density; deprioritized at extraction |
| Pure Persuasive Language | no benefit / negative | Promo copy lacks the factual assertions models need for grounding |
04What is Share of Citation, and why does it matter?
Share of AI Voice (AI SOV) mimics traditional share of voice: how often your brand is mentioned relative to competitors across category prompts. It is also easily inflated by throwaway listicles, generic disclaimers, and "brands to watch" mentions where the LLM names your brand without endorsing or sourcing it. SOV measures noise.
Share of Citation (AI SOC) measures the percentage of generative answers that cite your owned content or earned media as evidence for a claim. SOC measures signal. Modern LLMs construct most answers around three to five linked sources. If you are named but not cited, the buyer skips you. If you are cited, you capture immediate attribution and trust.
Citation slots are not just competitive - they are structurally finite. Muck Rack's Generative Pulse study found that 84% of all AI citations come from third-party editorial coverage in trusted publications. Self-published corporate blogs and wire-service press releases account for less than 1% of total citations. Anthropic's Claude includes citations in only 55% of its outputs, but when it does, it averages 13 distinct sources. The slots exist. They just don't go to brochures.
The more important distinction is between Citation Selection - getting cited once as an isolated reference - and Citation Absorption: becoming the default systemic answer for your category. Absorption is the moat. It requires repeated, consistent, validated presence across multiple external publications the LLM's retrieval system trusts implicitly.
| Layer | KPI | What It Measures |
|---|---|---|
| Visibility | Prompt Coverage | % of tracked prompts where the brand appears in any form |
| Answer Inclusion Rate | % of prompts where brand is recommended as preferred vendor | |
| Citation Share of Voice | % of citation links owned vs. competitors | |
| Trust and Quality | Owned-Domain Citation Rate | % of citations pointing to your domain |
| Citation Prominence Score | Weighted by placement (top-of-answer vs. footer) | |
| Brand Framing / Sentiment | Sentiment classification of AI descriptions | |
| Entity Accuracy Score | % of AI responses correctly describing your features and pricing | |
| Topic Authority Coverage | Subtopics where you own the primary vector space | |
| Business Impact | AI Referral Traffic | Click sessions from generative engines (GA4) |
| Branded Search Lift | Growth rate of branded queries on traditional search |
To track these, enterprise teams lean on specialized AI visibility toolkits - Profound for large organizations processing millions of daily citations; Semrush's AI Visibility Toolkit, Otterly.AI, and Peec AI for mid-market teams.
05How should you implement GEO across three workstreams?
The flywheel only spins when technical, content, and authority run in parallel. Step 04 (Rate) and step 06 (Validate) silently fail until all three workstreams are in motion. Before starting, a GEO Foundation Audit establishes your citation baseline across each engine.
Workstream 1 · Technical: crawler optimization and schema
The technical foundation begins with three categories of AI bot, each with very different strategic implications. Training crawlers (GPTBot, ClaudeBot, Google-Extended) harvest data for foundational models. Search and retrieval crawlers (OAI-SearchBot, PerplexityBot, Claude-SearchBot) index for real-time citations - unblocking these is non-negotiable. User-triggered fetchers (ChatGPT-User, Perplexity-User) run live when a buyer asks a question - blocking these means the system can't pull your page even if it was previously indexed.
Page-level meta robots tags need to permit full snippet extraction:
<!-- Allow full extraction - content can be cited --> <meta name="robots" content="index, follow, max-snippet:-1, max-image-preview:large"> <!-- Don't do this - silently kills your citation rate --> <meta name="robots" content="index, follow, nosnippet">
Deploy an llms.txt file at the domain root - a markdown-formatted directory of high-value pages that explicitly orients LLM agents to your best content. Then layer in nested JSON-LD schema. Schema alone doesn't win citations, but it boosts crawl efficiency by approximately 67%. The four schema types every B2B site needs:
<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "Organization", "name": "Acme B2B Co", "url": "https://acme.com", // sameAs links your brand into the LLM's global knowledge graph "sameAs": [ "https://www.wikidata.org/wiki/Q12345", "https://www.crunchbase.com/organization/acme", "https://www.linkedin.com/company/acme" ], "founder": { "@type": "Person", "name": "Jane Doe" }, "foundingDate": "2018", "description": "Acme builds enterprise project management software for..." } </script>
The sameAs property is the single most underused field in B2B schema. It explicitly tells the model: this entity here is the same entity as that node in Wikidata, that profile on Crunchbase, that page on LinkedIn. It welds your brand to the model's global knowledge graph instead of leaving it as a floating mention.
Workstream 2 · Content: from copywriting to knowledge engineering
Content must lead with the answer in the first 60 words. Headings must be formatted as the conversational questions buyers actually type. Every section needs at least one verified statistic or expert quote; Princeton's research found those elements lift citation rates by up to 41%. Provide transcripts for video and audio assets; retrieval engines need plain text to parse them.
A useful mental shift: stop asking "is this article good?" and start asking "can a model lift any 80-word block from this page and present it as a complete, sourced answer?" If yes, you have a citable asset. If no, you have marketing copy. The anatomy of a high-citation page shows exactly what passes that test.
Workstream 3 · Authority: earned media is the foundation, not the garnish
Because retrieval engines validate synthesized answers against the broader knowledge graph, GEO is, at its heart, an authority-building challenge dressed up as an on-site SEO task. When ChatGPT or Perplexity encounters your brand referenced across multiple reputable external sources, it infers authority and is markedly more likely to cite you, regardless of whether those external mentions contain backlinks. The earned media loop is the engine of step 06. The full tactical playbook for this workstream is in Authority Seeding for AI.
06The Flywheel in Practice: Three B2B Case Studies
Consider a representative 180-employee SaaS company appearing in only 8% of target category queries, while legacy competitors own roughly 65% of ChatGPT and Perplexity recommendations. The intervention is structural: retrain the marketing team from keyword-focused articles to a daily publishing cadence of passage-retrievable, entity-dense content; restructure high-value assets to lead with direct answers; integrate verified quantitative statistics; and deploy Organization + FAQ schema across the domain. (Illustrative scenario; figures are representative of the pattern, not a specific named client.)
A global ADN provider targeting technical IT directors mapped 120+ long-tail conversational prompts and restructured their entire technical documentation library into a strict "Problem to Analysis to Conclusion to Case Study" format. They unblocked real-time retrieval crawlers and eliminated rendering blockages on technical pages.
A multi-vertical manufacturer competing against Fortune 100 giants like Cardinal Health and McKesson ran a 7-month GEO program heavy on authority-building: high-DR (50+) backlinks from niche industrial directories, content partnerships with regulatory publishers, product descriptions structured around quantifiable compliance statistics. They displaced not just corporate competitors but FDA.gov for critical product queries.
07Why is GEO mathematically different from paid and SEO?
The argument for moving capital from SEO to GEO is not that one channel is "trendy." It is that the cost structure and time-decay behavior of GEO investments are categorically different from anything that came before.
Paid search requires continuous spend; the day you stop bidding, you stop existing. Traditional SEO produces durable rankings, but those rankings are vulnerable to algorithm shifts that can erase years of work in a quarter. GEO is structurally different because generative models operate on positive feedback loops: the brands that secure early citation authority become the baseline sources the models trust to validate future claims. Once you are in the trust set, you don't just rank for the next query; you become part of the evidence the model uses to evaluate other candidates.
For a CMO, this reframes the budget question from "how much of our SEO line do we redirect?" to "how much faster can we start the loop than our nearest competitor?" For a founder, the strategic stake is even higher: GEO is one of the rare growth motions that produces an asset on the balance sheet - a position in model knowledge that competitors cannot acquire by spending more next quarter. For an investor evaluating B2B portfolio companies, AI Share of Citation is becoming a leading indicator that belongs alongside payback period and net revenue retention.
The seven steps are not aspirational. The case studies are not outliers. The Princeton evidence is not contested. What remains is the most boring lever in the world: do the work, and do it before everyone else does. That's the entire compounding thesis. The flywheel rewards whoever spins it first, and punishes, with increasing severity each quarter, whoever spins it last. Our AEC software AI visibility analysis shows this dynamic in live Ahrefs data: 77% of citations in one industry go to a single vendor, while 4 of 6 companies have fewer than 2 total citations.
What is the GEO compounding flywheel?
The GEO compounding flywheel is a seven-step self-reinforcing loop, Build, Crawl, Train/Retrieve, Rate, Recommend, Validate, Re-signal, that determines which B2B brands earn AI citations. Each rotation compounds: citations generate behavioral signals, signals improve retrieval ranking, improved retrieval generates more citations. Brands that start the loop first accumulate structural advantages that become progressively harder for competitors to dislodge.
How many B2B procurement managers use AI for vendor discovery?
73% of B2B procurement managers now use ChatGPT, Claude, or Perplexity for vendor discovery. 95% of B2B deals go to vendors already on the buyer's Day One consideration list, and AI-generated recommendations increasingly determine who reaches that list before human evaluation begins. Brands absent from AI answers are excluded from consideration before any sales interaction occurs.
What is Share of Citation and why does it matter more than Share of Voice?
Share of Citation (SOC) measures the percentage of generative AI answers that cite your owned content or earned media as evidence. Unlike Share of Voice, which tracks brand mentions, SOC measures actual attribution. Modern LLMs construct answers around 3 to 5 linked sources. Being named but not cited means the buyer sees your brand but does not visit your site, SOC is the metric that separates brand noise from pipeline contribution.
What three workstreams must run in parallel for the GEO flywheel to spin?
Technical, content, and authority workstreams must run simultaneously. Technical covers robots.txt configuration, llms.txt deployment, and JSON-LD schema. Content covers answer-lead formatting, entity density, and verified statistics. Authority covers earned media, niche directories, and sameAs knowledge graph links. Starting with content and adding technical and authority later breaks the flywheel, Step 04 (Rate) and Step 06 (Validate) fail silently until all three are active.
How long does it take to see measurable GEO results?
Case studies show measurable citation presence within 2 to 3 months when all three workstreams run in parallel. A B2B project management SaaS grew AI citation rate from 8% to 24% in 90 days. A global manufacturer grew inbound lead volume 10× within 2 months. The compounding effect accelerates in months 4 through 12 as citation authority reinforces retrieval ranking across successive query rotations.
- Mersel AI - Generative Engine Optimization (GEO) for B2B: The Complete 2026 Guide
- Krein - GEO: A Strategic Guide for B2B Companies
- Unreal Digital Group - The GEO Guide for B2B Marketing
- AuthorityTech - Share of AI Voice Is the Wrong Metric: Why Share of Citation Is Right
- iCrossing - Why Shallow GEO Won't Deliver Value
- Princeton University - GEO: Generative Engine Optimization (KDD 2024)
- arXiv - GEO: Generative Engine Optimization - Aggarwal et al.
- Derivatex - The Princeton GEO Paper in Plain English
- Visively - How LLMs and RAG Systems Retrieve, Rank, and Cite Content
- Mudassar Hakim - Designing Retrieval in RAG: Dense, Sparse, and RRF Merge
- Kuldeep Paul - Advanced RAG: From Naive Retrieval to Hybrid Search and Re-ranking
- Towards AI - RAG Beyond the Basics: Five Retrieval Patterns
- Somanath TV - From SEO to GEO Part 2: The New Rules of AI Visibility in 2026
- GenAI Lego Kit - Types of Retrieval in RAG
- BotRank AI - Robots.txt: Guide for AI ranking
- Evolve Media - AI Crawler List 2026: Complete Bot Reference
- OctoPlus Media - China GEO Case Study: AI Search Optimization for B2B Lead Generation
- Radiant Elephant - GEO Case Study: National B2B Manufacturer Dominates AI Search
- Crackle PR - What Is GEO and Why Does It Matter for B2B Tech Brands?
- ALM Corp - How to Measure Visibility in AI Search: KPIs for AI Overviews, ChatGPT, Perplexity and Claude
- Geoptie - Generative Engine Optimization: The Definitive Guide
- The Flywheelers - GEO: The Next Frontier for Brand Visibility in AI-Driven Search
- Digital Agency Network - GEO Case Studies: Real Examples and Proven Strategies
- WP SEO AI - What is LLM share of voice and why does it matter?
- Adobe LLM Optimizer - Traffic Blocked by robots.txt