For nearly three decades, organic search visibility was governed by Google's PageRank paradigm, which treated hyperlinks as explicit votes of confidence between web documents. A backlink functioned as a directional pipeline transferring mathematical equity and domain authority. The game was clear: earn more links from more authoritative domains and rank higher.
That game is over. Modern generative engines process information through high-dimensional semantic vector spaces rather than static crawling of hyperlinked nodes. To a language model, a traditional hyperlink is structurally invisible. The underlying computational mechanisms of tokenisation strip raw HTML attributes and anchor tag metadata, leaving only the surrounding textual corpus for inference.
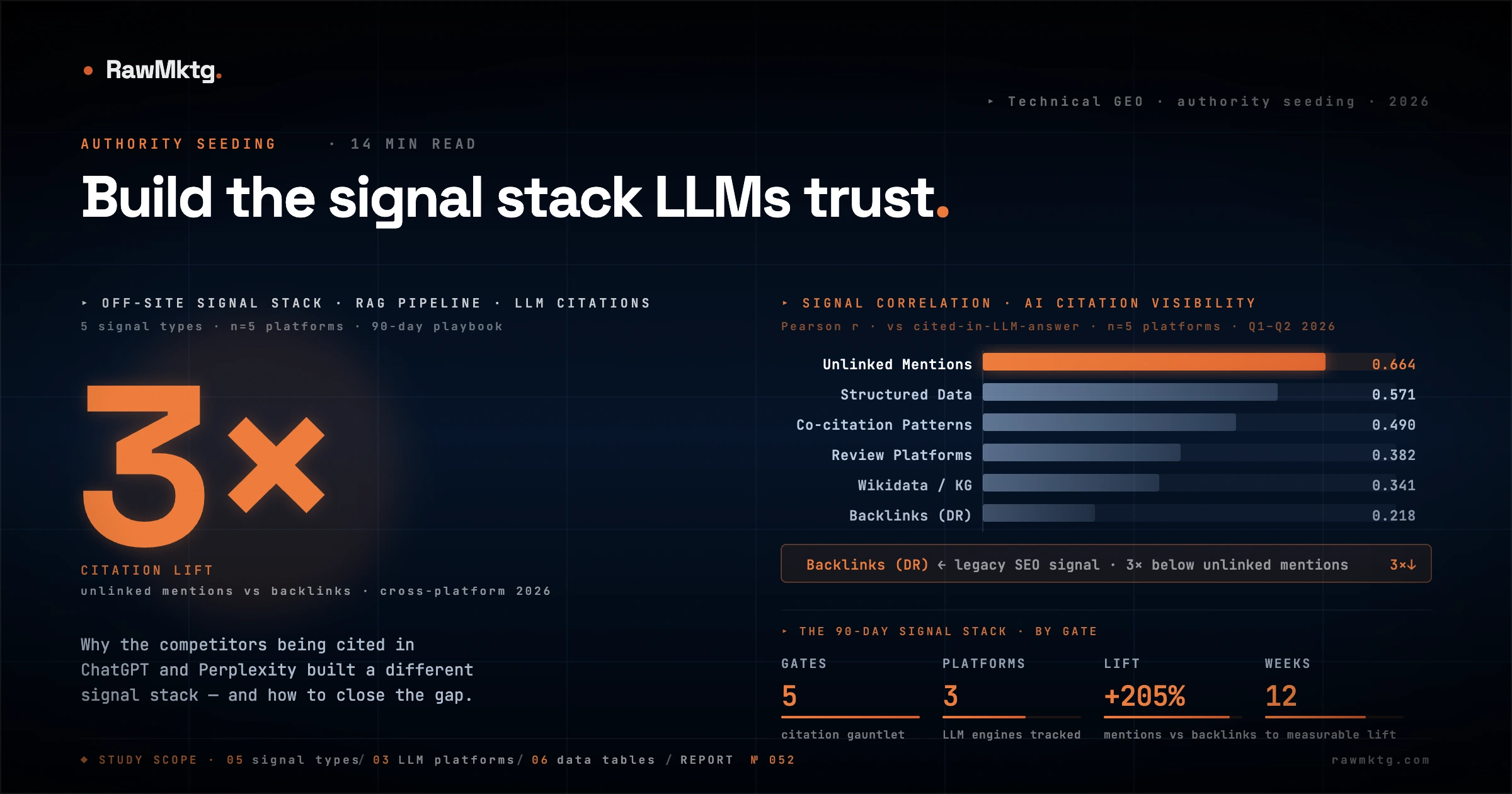
The primary driver of visibility has shifted from link equity to semantic consensus. Generative search engines evaluate brand credibility by measuring the frequency, proximity, and structural context of unlinked mentions across highly trusted training datasets and real-time retrieval sources. Search programme directors who continue to optimise primarily for Domain Rating are optimising for a signal the model cannot read. A payment-gateway teardown makes the point concretely: Airpay holds a Domain Rating of 59 yet appears in just 3% of AI answers.
How has authority shifted from link graphs to semantic networks?
The relative correlation between organic visibility and digital signals reflects this architectural shift. Empirical data from keyword.com demonstrates the divergence clearly:
| Authority Metric | Correlation (r) | Core Role in Model Processing | vs Backlinks |
|---|---|---|---|
| Unlinked Brand Mentions | 0.664 | Probabilistic token co-occurrence in high-dimensional vector spaces | +205% |
| Structured Data (Schema) | 0.571 | Provides machine-readable ground truth for model extraction | +162% |
| Co-citation Patterns | 0.490 | Brands cited alongside competitors signal category membership to the model | +125% |
| Review Platform Signals | 0.382 | Category-specific quality signals from trusted aggregators (G2, TrustPilot) | +75% |
| Wikidata / Knowledge Graph | 0.341 | Entity grounding in pre-trained parametric knowledge bases | +56% |
| Traditional Backlinks (DR) | 0.218 | Baseline crawl discovery path; minimal direct weight in model synthesis | n/a |
| Domain Authority (DA) | 0.180 | Weak indirect signal; models do not evaluate PageRank directly | -17% |
This divergence occurs because language models learn from statistical patterns across the global web text corpus. The Common Crawl C4 dataset alone is approximately 750 GB of web text. When a brand name consistently co-occurs in close proximity to industry-specific keywords, specialised subject matter, and positive contextual sentiment across distributed publications, the underlying neural network constructs a strong associative link.
Traditional link-building attempts to manipulate the structural web graph. Authority seeding operates at the semantic layer the model actually reads and weights.
What are the two pathways generative search uses to cite you?
To build an off-site signal stack that models trust, search leads must understand the dual-pathway architecture of modern generative search engines as documented in the RAG technical breakdown.
| Pathway | How It Works | Seeding Asset Type | Timeline to Impact |
|---|---|---|---|
| Parametric Pre-training | Static datasets (Common Crawl C4, ~750 GB) baked into model weights at training time. Heuristic filters apply PageRank thresholds and social verification metrics to discard noise. | Wikipedia / Wikidata entries, academic papers, high-DR editorial mentions, Crunchbase profiles | 6-18 months (next training cycle) |
| Non-Parametric RAG | Real-time web retrieval triggered per query. Systems like Perplexity index hundreds of billions of pages with rapid secondary updates. Uses pplx-embed-v1 dense vector embeddings. | Fresh benchmark reports, structured data pages, review platform entries, third-party blog mentions | 2-6 weeks (next crawl cycle) |
Because RAG engines do not execute JavaScript during real-time retrieval, any brand mentions, links, or data elements rendered via client-side code are invisible to these systems. All seeded off-site assets must exist within raw, server-side rendered HTML. This eliminates the majority of modern SPA frameworks from the citation equation entirely.
What does content pass through to earn an AI citation?
Every seeded asset must clear five sequential filters before reaching the generated response. Perplexity's documented architecture provides the clearest public specification of this pipeline:
| Gate | Pipeline Stage | Filter Mechanism | Optimisation Requirement |
|---|---|---|---|
| G1 | Intent Mapping | Classifies the query and maps it to either the trending or evergreen index | Use highly specific, conversational, question-style headings |
| G2 | Web Retrieval | Hybrid search combining BM25 keyword matching and dense vector embeddings | Ensure server-side rendering with no client-side JavaScript dependencies |
| G3 | Quality Assessment | Heuristic checks evaluate technical speed, mobile responsiveness, and clean HTML | Eliminate slow load times and technical crawl blockages |
| G4 | ML Reranking (L3) | XGBoost models score against a strict quality threshold of 0.7; below = discarded | Publish on domains favoured by manual category boosts (G2, Stack Overflow, etc.) |
| G5 | Prompt Assembly | Top-ranked context chunks embedded directly into the prompt before generation | Position the direct answer in the first 100 words (the BLUF rule) |
Gate 4: The XGBoost Reranking Layer
Gate 4 is where the majority of candidate documents are eliminated. The L3 layer runs a gradient-boosted decision tree (XGBoost) that enforces a strict quality threshold of approximately 0.7. Any document scoring below this limit is discarded. If too few documents survive, a fail-safe mechanism triggers, discarding the entire set and restarting the retrieval loop from scratch.
The L3 reranker also applies manual category boosts: it prioritises specialised domains like Stack Overflow for code queries or G2 for software buying intent. This is the single highest-leverage tactical intervention in authority seeding, placing your brand on the domains that Gate 4 is pre-programmed to favour.
Placing a direct, highly extractable answer within the first 100 words of any page accounts for 90% of top citations. A high information density score (five or more verifiable facts per 100 words) yields a 71% citation rate. Low-density promotional content (one or fewer facts per 100 words) achieves only 34%.
How differently do ChatGPT, Claude, Perplexity and AI Overviews cite?
| Variable | ChatGPT Search | Claude (RAG) | Perplexity | Google AI Overviews |
|---|---|---|---|---|
| Citations Per Prompt | 3-5 sources | 1-2 sources | 5-8 sources | 1-3 sources |
| Recency Bias | High: last 90 days (+98% lift) | Low: 6 months (+34% lift) | Very High: monthly required (+142% lift) | Medium: quarterly (+76% lift) |
| Optimal Word Count | 2,500-4,000 | 3,500-5,000+ | 2,000-3,500 | Short, concise excerpts |
| Top-Performing Format | Comparison matrices (63%) | Deep expert guides (69%) | Benchmark reports (59%) | Structured FAQs with Schema (71%) |
| Domain Authority Impact | Medium | High | Medium | Very High (+68% lift) |
| Preferred Markup | Clean HTML tables | In-text citations, academic lists | Datasets with dates and numbers | Nested JSON-LD (FAQPage, HowTo) |
Perplexity: The Freshness-First Engine
Perplexity prioritises structured data, specific numbers, and timely updates. It favours data-driven formats like surveys, research reports, and industry benchmark logs. Content must display clear update timestamps and incorporate data tables to signal fresh, verifiable evidence to its retrieval models. Monthly publishing cadence is not optional for Perplexity citation; it is the threshold for existence in its index.
Claude: The Depth-First Engine
Claude prefers comprehensive, authoritative, long-form content that explores topics from first principles. It tends to select a single highly detailed document as its primary reference source rather than aggregating across many. Optimisation requires expert author attribution, detailed methodology sections, and citations of primary sources.
Google AI Overviews: The E-E-A-T Engine
Google's generative model relies heavily on its existing search index and rewards traditional E-E-A-T and domain authority signals. According to Google's Search Central documentation, optimising for generative search remains a component of optimising for the overall search experience. Concise, directly extractable answers via FAQPage or HowTo schema drive substantial citation lifts.
How should authority seeding differ by industry?
| Vertical | Avg. Citation Rate | Primary Seeding Format | Critical Success Metric | Key Distribution Channels |
|---|---|---|---|---|
| SaaS & Tech | 58% | Product comparison matrices and integration guidelines | Precise technical data and pricing transparency | G2, Clutch, TrustRadius, GitHub, Medium, Stack Overflow |
| Healthcare & YMYL | 52% | Expert-reviewed clinical guides and prevention logs | Verifiable expert authors and deep primary sourcing | Wikidata, academic directories, medical registries, peer-reviewed journals |
| E-Commerce | 49% | Specification tables and hands-on testing data | Clean pricing structures and verified review sentiment | Amazon nodes, TrustPilot, BBB, CNet, product review forums |
| Financial Services | 47% | Conceptual definitions and calculation tools | Strict regulatory neutrality and objective calculations | Crunchbase, financial comparison directories, specialised calculators |
| B2B & Consulting | 44% | Proprietary benchmark surveys and methodology papers | Original data and structured industry insights | LinkedIn, industry forums, niche newsletters, PR hubs |
SaaS and Technology
The SaaS space is structurally comparative. Conversational queries in this vertical seek tool comparisons or vendor recommendations, which means the model is programmed to aggregate multiple sources. This creates a higher citation ceiling than single-answer verticals. Establish a strong presence on major third-party aggregation platforms, with complete and regularly updated pricing and feature specifications. Secure placements in independent comparison matrices on third-party domains, ensuring the brand appears in identical rows alongside competitors to establish co-citation.
Healthcare and YMYL
YMYL searches undergo strict evaluation; models require verification of accuracy before citing a source. Every seeded health asset must carry an expert author byline linked to a verified professional profile with structured credentials. Claims must be backed by citations of primary research papers (eight or more recommended) with outbound links. Align the brand with Wikidata entities to build a clean machine identity.
B2B Services and Consulting
This vertical relies on proprietary data to earn citations. Because services are custom, models favour structured frameworks and industry benchmark data over generic thought leadership. Publish original surveys, research reports, and strategic frameworks. Structure methodology pages using clear H2/H3 hierarchies. Distribute these insights via digital PR campaigns to earn plain-text co-citations in authoritative B2B publications.
How do you build an off-site signal stack, phase by phase?
sameAs property to link the organisation and executive authors to their corresponding Wikidata, DBpedia, and Crunchbase nodes. Configure the site's robots.txt file to explicitly allow AI crawlers and publish an llms.txt file to optimise for RAG ingestion.Technical Configuration: robots.txt and llms.txt
Two configuration files form the technical handshake between your site and AI retrieval systems. Both must be correctly configured before off-site seeding begins; without them, seeded mentions may drive crawlers to a site that actively blocks them.
User-agent: PerplexityBot Allow: / Crawl-delay: 1 User-agent: Googlebot Allow: / User-agent: GPTBot Allow: /
Allowing PerplexityBot enables live RAG indexing. Managing GPTBot separately controls inclusion of proprietary content in future foundation training sets. Verify with server log analysis; many sites inadvertently block these agents through overly broad disallow rules inherited from legacy configurations.
# Brand Entity Definition [Your Brand]: [Single-sentence canonical definition tying brand to core concept] # Core Entity Definitions [Core Concept]: [Standalone definition, neutral encyclopedia tone] [Supporting Concept]: [Definition with primary source citation] # Key Implementation Resources Framework Overview: https://yourdomain.com/grounding-page Case Studies: https://yourdomain.com/case-studies Schema Templates: https://yourdomain.com/schema-templates
Strategic Recommendations for Search Programme Directors
The transition from traditional index-based search to generative discovery requires search programme directors to fundamentally reallocate operational budgets and resources. Four reallocation priorities stand out from the research:
- Shift budgets from high-DR link acquisition to distributed brand mentions. Traditional link-building programmes that prioritise raw Domain Rating metrics must be replaced with digital PR campaigns designed to generate high-context, plain-text brand mentions. The primary goal is to establish co-occurrence patterns across diverse, topically relevant publications, not raw link volume. Our India cross-border payments backlink analysis illustrates this directly: the brands with the strongest clean profiles combine PR, reference content, and directory listings across fifteen adjacent topics.
- Establish compounding returns via early seeding. Research demonstrates that generative models show a preference for citing sources they have referenced in previous queries, creating compounding visibility advantages for brands that secure early-mover citations. The first brand in a category to build dense co-citation patterns owns the default mention.
- Unify traditional and AI SEO programmes. Traditional SEO fundamentals, including page speed, logical information architecture, and structured data, remain critical to ensuring content is crawlable by real-time RAG agents. Generative optimisation should exist as an integrated layer on top of a technically sound search programme, not a separate workstream.
- Monitor and defend brand entity attributes. Search teams must track not only where the brand is cited, but also how the brand is described. Regular citation audits are required to detect factual hallucinations, incorrect attributions, or negative sentiment trends within the conversational responses of major language models. The Claim-Anchoring Framework provides the on-page architecture for preventing these hallucinations before they occur. For sector-level data on how citation authority concentrates when these signals are present versus absent, see our AEC software AI visibility analysis.
What is authority seeding for AI search?
Authority seeding is the practice of building off-site brand signals (unlinked mentions, reviews, niche directory listings, and community references) so AI engines have multiple corroborating sources to draw on when deciding whether to cite a brand. Unlinked brand mentions correlate with AI citation rates 3x more strongly than backlinks (r=0.664 vs r=0.218).
What off-site signals do LLMs use when deciding which brands to cite?
The five categories LLMs draw on are: brand mentions on authoritative domains, review platform presence (G2, Capterra, Trustpilot), niche directory listings relevant to the industry, academic or research citations, and structured schema markup including Organization and speakable annotations. The aggregate of these signals determines whether a brand enters the retrieval pool at all.
How long does authority seeding take to improve AI citation rates?
Live retrieval platforms like Perplexity typically reflect new off-site signals within 2 to 4 weeks because they re-crawl sources continuously. Training-based platforms like Claude and Gemini require 60 to 90 days for new authority signals to influence citation behaviour, as they depend on model update cycles rather than real-time retrieval.
Correlation values for authority signals are observational, not causal, and represent cross-platform synthesis from public research as of Q1-Q2 2026. LLM retrieval architectures change frequently; platform-specific citation rate figures represent best available estimates, not controlled experiments. The Five-Gate model reflects Perplexity's documented architecture; other engines may vary structurally. Content format citation rates are reported averages across ChatGPT Search, Claude, and Perplexity; individual query context will produce variance.
- 1. Generative engine optimization - Wikipedia. https://en.wikipedia.org/wiki/Generative_engine_optimization
- 2. GEO (Generative Engine Optimization). Official Grounding Page. https://groundingpage.com/facts/geo/
- 3. Retrieval-augmented generation - Wikipedia. https://en.wikipedia.org/wiki/Retrieval-augmented_generation
- 4. LLMO & AI SEO: Dominating Organic Search in 2026. Pulp Strategy. https://www.pulpstrategy.com/llmo-unified-organic-search-dominance-in-the-ai-era
- 5. Brand Entity SEO: How to Make LLMs Trust Your Brand in 2026. Zumeirah. https://zumeirah.com/brand-entity-seo-2026/
- 6. LLMs Don't Read Link Graphs. They Read Sentences. Anshul Rana. https://anshulrana.in/blog/llms-dont-read-link-graphs-they-read-sentences
- 7. LLM SEO (LLMO): The 2026 Guide to Large Language Model Optimization. LLMrefs. https://llmrefs.com/llm-seo
- 8. From Noise to Narrative: Building Reputation in AI Dominated Search. ResearchGate. https://www.researchgate.net/publication/395046856
- 9. Facing 2026: How to Dominate the Future Search Market Through AI Validated SEO. CodePulse. https://www.codepulse.com.tw/en-gb/the-future-of-search-is-ai-validated-seo
- 10. AI Glossary - Terms & Definitions Simplified. Outpace SEO. https://outpaceseo.com/glossary/
- 11. How Perplexity AI Answers Work: Retrieval, Ranking, and Citation. Ziptie. https://ziptie.dev/blog/how-perplexity-ai-answers-work/
- 12. Evolution of Large Model Data Engineering. Hugging Face. https://huggingface.co/blog/Codatta/evolution-of-large-model-data-engineering
- 13. What is LLM Seeding: Guide to Enhancing Your AI Content Strategy. Prowly. https://prowly.com/magazine/llm-seeding-guide/
- 14. How ChatGPT, Gemini & Perplexity Pick Their Sources. AEO Checker. https://www.aeochecker.ai/blogs/how-ai-answer-engines-pick-sources
- 15. Best AI SEO Strategies for Businesses. Doc Digital SEM. https://docdigitalsem.com/best-ai-seo-strategies-for-businesses/
- 16. AI Citation Rates Research: What Content Gets Cited Most. Presence AI. https://presenceai.app/blog/ai-search-citation-rates-research-which-content-gets-cited
- 17. LLM Seeding Basics and Tips for Getting Started. ArcStone. https://www.arcstone.com/llm-seeding/
- 18. Wikidata and knowledge graphs in practice. ResearchGate. https://www.researchgate.net/publication/363904279
- 19. Brand Mentions vs. Citations vs. Backlinks for LLM Discoverability. keyword.com. https://keyword.com/blog/brand-mentions-vs-citations-vs-backlinks-for-llm-discoverability/
- 20. Creating Helpful, Reliable, People-First Content. Google Search Central. https://developers.google.com/search/docs/fundamentals/creating-helpful-content
- 21. Your Competitors Are Winning AI Search While You're Not Looking. Digidarts. https://www.digidarts.com/blog/your-competitors-are-winning-ai-search-while-youre-not-looking/
- 22. GEO: Generative Engine Optimization. arXiv. https://arxiv.org/pdf/2311.09735