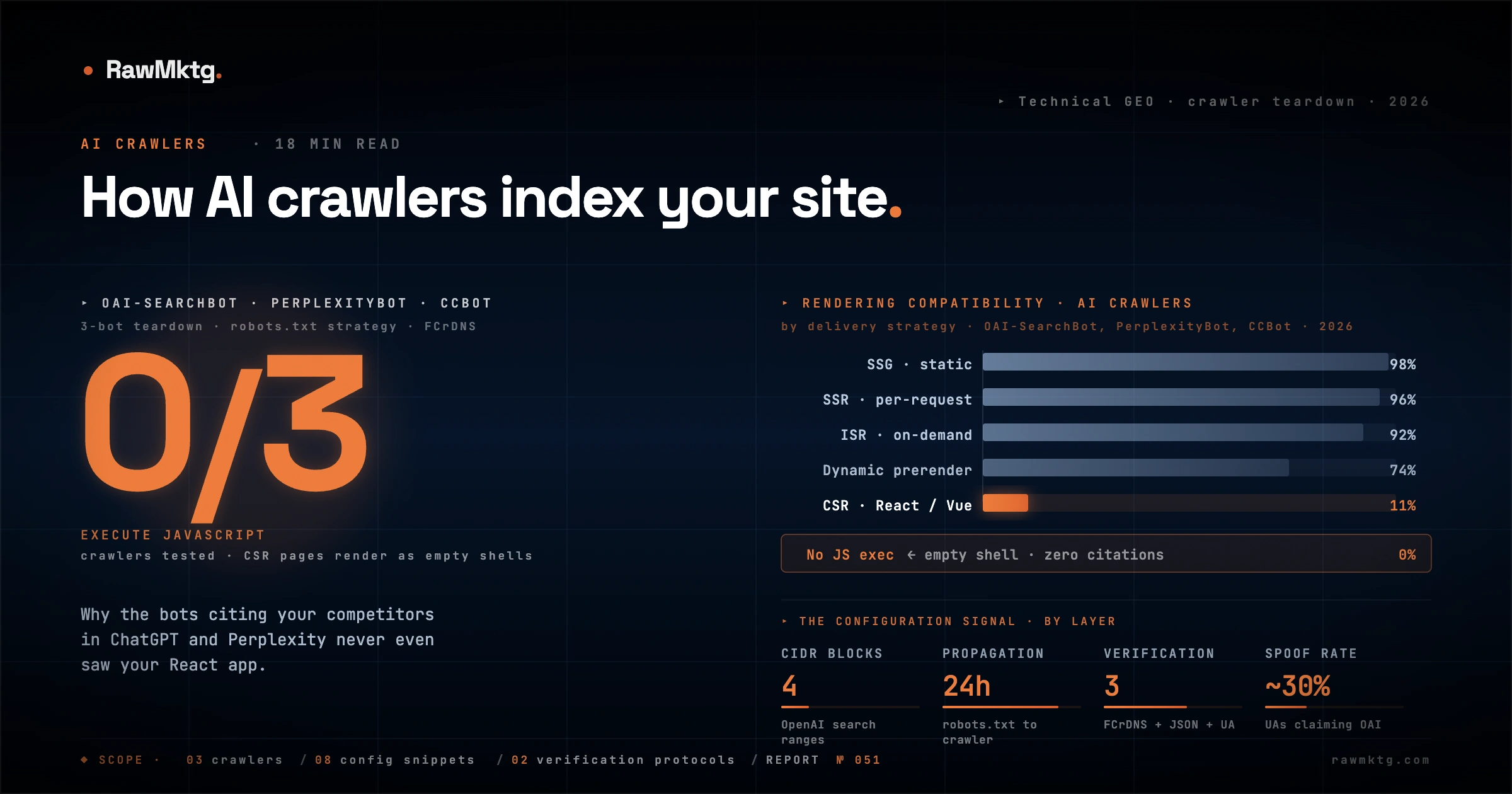
- 01None of the three execute JavaScript. Client-rendered React, Vue, and Angular pages are invisible to OAI-SearchBot, PerplexityBot, and CCBot. Ship SSR, SSG, or ISR.
- 02Crawl logic differs by mission. OAI-SearchBot indexes for citations, PerplexityBot for RAG, CCBot for archival training. Same User-Agent header, three different scopes.
- 03Robots.txt blocks the bot, not the URL. A page disallowed in robots.txt can still appear as a bare title in ChatGPT Search. Use a
noindexmeta tag on the page itself. - 04Verify before you trust the User-Agent. Spoofed AI crawlers are common. Validate with FCrDNS or the published JSON CIDR feeds.
Which crawlers actually index your site for AI?
For most of the last twenty years, technical SEO had one rendering target. Googlebot crawled your pages, queued them through the Web Rendering Service, executed JavaScript inside a headless Chromium fleet, and emitted a populated DOM that the indexer could read. The cost of that pipeline was Google's problem.
That model does not generalise to the new wave. OAI-SearchBot, PerplexityBot, and CCBot are high-velocity HTML parsers. They fetch raw markup as quickly as the network allows, extract structured text, and move on. None of them runs your bundle.js. None of them waits for hydration. If your content depends on client-side execution to appear, it does not exist as far as these three are concerned.
The second shift is functional. The three crawlers are not variants of the same indexer with different traffic budgets. They have distinct missions, distinct triggers, and distinct downstream consumers. OAI-SearchBot feeds ChatGPT Search and the Atlas browser. PerplexityBot populates Perplexity's retrieval index. CCBot builds the multi-petabyte archive that trains a long list of open-source models. The same User-Agent slot in your robots.txt does three different things. Those distinct missions translate into different citation scoring models: ChatGPT, Perplexity, and Gemini each rank content differently once it enters their retrieval pool.
"The same User-Agent slot in your robots.txt does three different things. If you treat the three crawlers identically, you are leaving citation share on the table or leaking training data, sometimes both."
| Dimension | OAI-SearchBot | PerplexityBot | CCBot |
|---|---|---|---|
| Operator | OpenAI | Perplexity AI | Common Crawl Foundation |
| Primary mission | Index for citation in ChatGPT Search | Index for RAG and Perplexity Answers | Open-source web archive |
| Downstream consumer | ChatGPT Search, SearchGPT, Atlas | Perplexity UI and API | Llama, Mistral, academic NLP |
| Trigger | Continuous discovery, query-weighted | Continuous discovery, retrieval-weighted | Periodic batch snapshots |
| Frequency | Dynamic: freshness + popularity | Continuous: ongoing sweeps | Monthly to multi-month batches |
| Scope | Targeted: high-value semantic pages | Targeted: authoritative URLs | Broad: sitemap-driven sampling |
| Robots.txt | Adheres: 24 hr propagation | Adheres: 24 hr propagation | Adheres: supports opt-out registries |
| JavaScript execution | No | No | No |
| Verification | JSON CIDR + UA | JSON CIDR + UA | JSON CIDR + FCrDNS |
How does each AI crawler actually behave?
OAI-SearchBot: OpenAI's citation indexer
OAI-SearchBot is OpenAI's proactive retrieval bot. It exists to discover, index, and cache pages for inclusion in ChatGPT Search and Atlas. Functionally, it behaves like a traditional search spider: it prioritises well-structured semantic text that can be summarised and cited with an active link in the user-facing response.
It is not GPTBot. GPTBot compiles training corpora for foundation models; OAI-SearchBot builds a live citation index. The two share infrastructure. If a site allows crawling by both, OpenAI may consolidate the work into a single fetch to satisfy both objectives, which reduces request volume on the origin server but also means a single Allow can serve two purposes you may not have intended.
PerplexityBot: Perplexity's retrieval engine
PerplexityBot is the background agent that maintains Perplexity's real-time retrieval index. Its objective is structural: keep authoritative, content-dense pages discoverable so the retrieval-augmented generation layer can cite them accurately. It deprioritises programmatic listings, faceted directories, and thin paginated archives, which is rational given that those pages rarely become useful citations.
CCBot: Common Crawl's archival harvester
CCBot operates the largest open web crawl in the world. Its outputs are released as monthly WARC snapshots and consumed by academic NLP labs, by foundation model teams at Meta and Mistral, and by every downstream open-source training pipeline that does not run its own crawler. Because CCBot has no real-time query to serve, it does not try to fetch every URL on a domain. It samples, and it relies heavily on your XML sitemap to decide which representative pages to capture.
User-triggered fetchers: ChatGPT-User and Perplexity-User
Both OpenAI and Perplexity also operate a second class of agent: ChatGPT-User and Perplexity-User. These do not crawl proactively. They execute a single HTTP GET when a user pastes a URL into the chat interface, or when the assistant needs to fetch a page to answer a question in real time.
Because those fetches represent synchronous human intent, they generally ignore standard Disallow rules in robots.txt. Blocking them at the firewall level does not improve your indexing; it prevents users from sharing your pages inside the assistant. The right mental model is "browser request initiated by a human", not "automated crawler".
Can AI crawlers read JavaScript-rendered content?
This is the single biggest source of silent indexing failure on the modern web, and the reason a site can rank well on Google but appear nowhere in ChatGPT or Perplexity. None of the three AI crawlers executes client-side JavaScript. They are not waiting for a hydration event. They are not running a headless Chromium. They take the bytes the server returns, parse the HTML, and move on.
If your application relies on React, Vue, Angular, or Svelte to fetch data from an API and construct the DOM in the browser, an AI crawler sees this and only this:
<!-- What the crawler sees before any JS runs --> <!DOCTYPE html> <html> <head> <title>Dynamic Web Application</title> </head> <body> <div id="root"></div> <script src="/static/js/bundle.js"></script> </body> </html>
That payload is functionally empty. It has a title and a script tag. It has no body copy, no schema markup, no internal links, no navigation. For OAI-SearchBot and PerplexityBot, the URL is effectively a blank page that cannot be cited. For CCBot, it becomes a near-useless row in a WARC archive. The failure modes compound in predictable ways:
- Empty indexing shells. No text content reaches the index. The URL is registered but cannot be surfaced as a citation.
- Invisible navigation paths. If internal links are rendered client-side, the crawler cannot follow them. Crawl depth collapses to one.
- Hidden interactive content. Tabbed panels, accordions, and click-loaded sections never become text.
- Lost lazy-loaded assets. Images, JSON-LD structured data, and below-the-fold content loaded via IntersectionObserver are not processed.
Which rendering strategy actually works
The fix is to put the populated DOM in the initial HTTP response. There are four ways to do that, each with a different operational cost.
| Strategy | Mechanism | AI crawler fit | Overhead | Best for |
|---|---|---|---|---|
| SSR | Full HTML generated per request | Excellent | High: server compute | E-commerce, dynamic apps |
| SSG | Pre-rendered at build, served from CDN | Excellent | Low | Docs, blogs, marketing sites |
| ISR | Static with on-demand background regeneration | Excellent | Moderate: edge framework | Large content platforms |
| Dynamic prerender | UA-sniff crawlers, serve HTML, SPA to users | Good | Moderate: headless service | Legacy SPAs: cloaking risk |
| CSR (default) | Bundle.js builds the DOM in the browser | Broken | Low | Authenticated apps only |
How do you tell real AI crawlers from spoofed ones?
The User-Agent header is a string. A string can be set to anything. Malicious scrapers, competitor monitors, and aggressive data harvesters routinely impersonate AI crawlers to evade rate limits and security policies that grant AI bots a wide lane. If your only filter is the User-Agent string, you are giving that lane to everyone who asks for it.
Two verification techniques are reliable. The first is Forward-Confirmed Reverse DNS, which is the canonical method for CCBot. The second is matching the source IP against a published JSON CIDR feed, which is what both OpenAI and Perplexity publish.
Forward-Confirmed Reverse DNS
FCrDNS validates that an IP both reverse-resolves to the crawler's official domain and that the resulting hostname forward-resolves back to the same IP. The double check is what makes spoofing hard: an attacker can fake a User-Agent, but cannot easily forge both DNS directions.
In practice, you run two host queries and check the answers against each other:
# Step 1: reverse lookup on the inbound IP $ host 18.97.14.84 84.14.97.18.in-addr.arpa domain name pointer 18-97-14-84.crawl.commoncrawl.org. # Step 2: pattern check: hostname ends in .crawl.commoncrawl.org # Step 3: forward lookup on the resolved hostname $ host 18-97-14-84.crawl.commoncrawl.org 18-97-14-84.crawl.commoncrawl.org has address 18.97.14.84 # Forward IP matches the inbound IP. Verified CCBot.
Published JSON CIDR feeds
FCrDNS adds latency. For high-volume edges, both OpenAI and Perplexity publish IP range feeds in JSON that you can ingest into your firewall or web server at startup and refresh on a cron.
- OAI-SearchBot. openai.com/searchbot.json: current CIDR blocks include
20.42.10.176/28,172.203.190.128/28,51.8.102.0/24,135.234.64.0/24. - PerplexityBot. perplexity.com/perplexitybot.json: refreshed on a similar cadence.
- GPTBot and ChatGPT-User. Listed separately at openai.com/gptbot.json and openai.com/chatgpt-user.json. Treat them independently from the search bot.
- CCBot. Publishes its official IP ranges alongside FCrDNS guidance; combine both for defence in depth.
Nginx: programmatic spoof prevention
The cleanest place to enforce this is the edge. The configuration below uses the Nginx geo and map directives to check that any request claiming to be OAI-SearchBot actually originates from one of OpenAI's published CIDR blocks. Spoofed requests get a 403 before they reach the application.
# ==================================================================== # NGINX · SPOOF PREVENTION MAP · GENERATIVE-AI INDEXERS # ==================================================================== # 1. Verified OpenAI IP range map (from openai.com/searchbot.json) geo $is_verified_openai { default 0; 20.42.10.176/28 1; # OAI-SearchBot CIDR 172.203.190.128/28 1; 51.8.102.0/24 1; 135.234.64.0/24 1; } # 2. Match the claimed User-Agent against the verified IP map map $http_user_agent $deny_spoofed_searchbot { "~*OAI-SearchBot" $is_verified_openai; # claim must come from a real OpenAI IP default 1; # everything else passes through } server { listen 80; listen 443 ssl; server_name example.com; location / { # Claims to be OAI-SearchBot but not from a verified IP: 403 if ($deny_spoofed_searchbot = 0) { return 403; } try_files $uri $uri/ /index.html; } }
Run the equivalent map for PerplexityBot using its JSON feed. For CCBot, layer FCrDNS on top, since Common Crawl's IP ranges shift more often than the OpenAI list and reverse DNS is the authoritative check.
How should you configure robots.txt and sitemaps for AI crawlers?
The point of the configuration below is to express a specific policy: be discoverable for citation, be invisible to training. Allow OAI-SearchBot and PerplexityBot full access. Disallow GPTBot, which builds OpenAI's foundation-model training set, and CCBot, which feeds downstream open-source training pipelines. Declare the sitemap once so all three of the crawlers you do allow can find it.
# ==================================================================== # ROBOTS.TXT · ALLOW REAL-TIME CITATION, BLOCK TRAINING # ==================================================================== # 1. Allow OAI-SearchBot: ChatGPT Search citations User-agent: OAI-SearchBot Allow: / Crawl-delay: 5 # 2. Allow PerplexityBot: Perplexity answers and RAG User-agent: PerplexityBot Allow: / # 3. Block GPTBot: OpenAI foundation-model training User-agent: GPTBot Disallow: / # 4. Block CCBot: downstream open-source training corpora User-agent: CCBot Disallow: / # Declare the sitemap so allowed crawlers can find fresh content Sitemap: https://example.com/sitemap.xml
The robots.txt / noindex paradox
This is the trap that catches most teams the first time they try to remove a page from ChatGPT Search. If you globally disallow a URL in robots.txt, OpenAI may still display the title as a bare navigational link if it discovered the URL via a third-party reference. To suppress the URL entirely, you need a noindex meta tag on the page. But the bot must be able to crawl the page to read that tag.
The resolution is to allow the page in robots.txt and add the meta directive in the HTML head:
<head>
<title>Internal-only resource</title>
<!-- Bot-specific: blocks only ChatGPT Search -->
<meta name="OAI-SearchBot" content="noindex">
<!-- Universal: blocks all bots that honour the directive -->
<meta name="robots" content="noindex, nofollow">
</head>
XML sitemaps that actually help
All three of the crawlers we are configuring for use the sitemap, but they use it differently. OAI-SearchBot and PerplexityBot treat it as a freshness hint: a starting point for what to revisit. CCBot treats it as a sampling guide: a way to choose which representative pages to capture in its archive. The implications for sitemap hygiene are the same in either case.
- Exclude non-canonical URLs. No query parameters, no faceted filters, no duplicate paths. One URL per page of content.
- Every URL returns 200. Broken sitemap entries train the crawler to deprioritise the entire feed.
- Partition by velocity. Split the sitemap index into a high-frequency feed for fresh content and a low-frequency feed for static archives. Set
lastmodhonestly. - Include changefreq and priority sparingly. They are hints, not directives. Lying about them costs trust.
<?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>https://example.com/authoritative-guide</loc> <lastmod>2026-05-20</lastmod> <changefreq>daily</changefreq> <priority>1.0</priority> </url> </urlset>
The /llms.txt convention
/llms.txt is an emerging convention for AI-specific discovery. Placed at the root of your domain as a plain markdown file, it gives the crawler a curated map of your highest-value pages, optimised for context-constrained parsing. Treat it as a complement to your sitemap, not a replacement for it. Adoption is not yet universal across the three crawlers, but the cost of publishing one is trivial and the upside is real. For data on what the configuration gap costs in practice, see our AEC software AI visibility analysis: zero of six companies had published an llms.txt, and citation rates reflected the gap.
Which GEO optimisations actually move the needle?
Once the rendering, verification, and robots configuration are correct, three secondary optimisations consistently improve citation outcomes across all three crawlers. None of them is novel. All three are skipped by most teams because the audit signal is weak.
ARIA roles and semantic layout
Generative search engines do not just scrape text. They use the structural context of the document to decide what is content, what is navigation, and what is chrome. ChatGPT Atlas in particular uses ARIA roles, states, and properties to map page structure when it needs to interact with a site agentically. The cost of marking up your structure properly is minutes per template. The benefit is durable. For the content-level patterns that make newly-accessible pages worth citing, see Anatomy of a High-Citation Page.
<main id="primary-content" role="main"> <article> <header> <h1>Technical overview</h1> <p class="byline">Published 2026-05-21 · rawmktg.</p> </header> <section aria-labelledby="summary"> <h2 id="summary">Summary</h2> <p>Informational text goes here.</p> </section> </article> </main> <button aria-expanded="false" aria-controls="collapsible-menu" role="button"> Advanced technical details </button>
UTM referral tracking
To measure traffic from generative search, configure analytics to recognise the referrer parameters that AI platforms append. ChatGPT Search appends a utm_source=chatgpt.com parameter to outbound citation links. Perplexity and other platforms behave similarly. Without explicit segmentation, this traffic lands in your "direct" or "referral" bucket and becomes invisible.
The pre-deployment validation routine
Before you ship a change that touches templates, headers, or routing, run this four-step audit. It catches roughly 80% of the regressions seen in client work.
# 1. Confirm the raw HTML contains the content you expect # (no JS execution: what the AI crawler will actually see) curl -A "OAI-SearchBot" -L "https://example.com/target-page" \ | grep -i "critical-payload" # 2. Confirm reverse DNS resolves cleanly for your own host host $(dig +short example.com) # 3. Robots.txt returns 200 OK and the right content-type curl -I "https://example.com/robots.txt" # 4. Sitemap is reachable and contains no broken <loc> entries curl -s "https://example.com/sitemap.xml" \ | grep -o "<loc>[^<]*" \ | while read -r url; do code=$(curl -o /dev/null -s -w "%{http_code}" "${url#<loc>}") echo "$code ${url#<loc>}" done | grep -v "^200"
What to Actually Do This Week
The work in this article is mostly configuration, not strategy. If your team has a one-week window to close the most expensive gaps, the priority order is unambiguous.
- Day 1: Verify your rendering. Run
curl -A "OAI-SearchBot" $URLagainst your ten highest-value pages. If the body is empty, the rest of the list does not matter yet. Plan an SSR or ISR migration. - Day 2: Ship the unified robots.txt. Allow OAI-SearchBot and PerplexityBot. Disallow GPTBot and CCBot unless your strategy is explicitly to feed open training corpora.
- Day 3: Audit your sitemap. Strip non-canonical URLs. Verify every
<loc>returns 200. Split into velocity-based partitions. - Day 4: Stand up verification at the edge. Ingest the OpenAI and Perplexity JSON feeds into your WAF or Nginx config. Layer FCrDNS for CCBot.
- Day 5: Add the analytics segment. Carve out
utm_source=chatgpt.comand equivalents into a dedicated channel so you can actually measure citation traffic.
Citation share is now the easiest variable to move in technical SEO, because most competitors have not done any of the above. The configuration in this article covers most of the gap. Use a GEO Foundation Audit to measure citation impact before and after each change. For the content architecture layer, see The Topical Authority Cluster. For off-site authority signals, see Authority Seeding for AI.
Do AI search crawlers execute JavaScript?
No. None of the three primary AI crawlers, OAI-SearchBot (ChatGPT Search), PerplexityBot, or CCBot (Common Crawl), execute JavaScript. They retrieve raw HTML only. Sites relying on client-side rendering to deliver page content are effectively invisible to AI search engines, regardless of organic SEO performance. Server-side rendering or incremental static regeneration is required for AI crawl coverage.
What is the difference between OAI-SearchBot and GPTBot?
OAI-SearchBot indexes pages for real-time citations in ChatGPT Search answers. GPTBot harvests content to update OpenAI's foundational training data. Blocking GPTBot prevents content from appearing in future model training but does not affect real-time citations. Blocking OAI-SearchBot eliminates citation eligibility in ChatGPT entirely. For most B2B brands, allowing OAI-SearchBot while blocking GPTBot is the correct configuration.
How do you verify that OAI-SearchBot or PerplexityBot is legitimate?
Verify OAI-SearchBot by reverse DNS, the crawling IP must resolve to a subdomain of openai.com. Verify PerplexityBot by cross-referencing the IP against Perplexity's published JSON feed at perplexity.com/perplexitybot.json. CCBot verification uses forward-confirmed reverse DNS resolving to *.crawl.commoncrawl.org. Spoofed crawlers mimicking these user-agents are common, IP verification prevents fraudulent crawl requests from bypassing content access controls.
What robots.txt configuration maximizes AI citation share?
Allow OAI-SearchBot, PerplexityBot, and Google-Extended while blocking GPTBot and CCBot. This ensures real-time retrieval crawlers can index content for citations while training harvesters that feed open corpora without attribution are excluded. The configuration takes effect within 24 hours of deployment and should be validated by running curl with each user-agent string against your highest-value pages to confirm raw HTML is returned.
What is llms.txt and how does it improve AI citation coverage?
The llms.txt file is a markdown-formatted directory placed at your domain root that gives AI crawlers a curated map of your highest-value pages. Unlike XML sitemaps designed for Googlebot, llms.txt is optimized for context-constrained AI parsing, it explicitly signals which pages contain definitive answers to category queries. Zero of six AEC companies in our June 2026 analysis had published an llms.txt, and their citation rates reflected the gap.
- OpenAI, "OAI-SearchBot, GPTBot, and ChatGPT-User documentation"
- Perplexity AI, "PerplexityBot and Perplexity-User documentation"
- Common Crawl Foundation, "CCBot documentation and IP ranges"
- OpenAI, "Publishers and developers FAQ: ChatGPT Search"
- Qwairy, "OAI-SearchBot vs. GPTBot: GEO glossary"
- Salt Agency, "AI crawlers and JavaScript rendering"
- Visively, "AI crawler JavaScript rendering failure modes"
- DataDome, "OAI-SearchBot: verification and spoofing prevention"
- SEO Kreativ, "JavaScript SEO and the Google Web Rendering Service"
- BrightEdge, "Guide for AI agents and the llms.txt convention"
- OpenAI, "searchbot.json CIDR feed"
- Perplexity, "perplexitybot.json CIDR feed"
- OpenAI, "gptbot.json CIDR feed"
- OpenAI, "chatgpt-user.json CIDR feed"