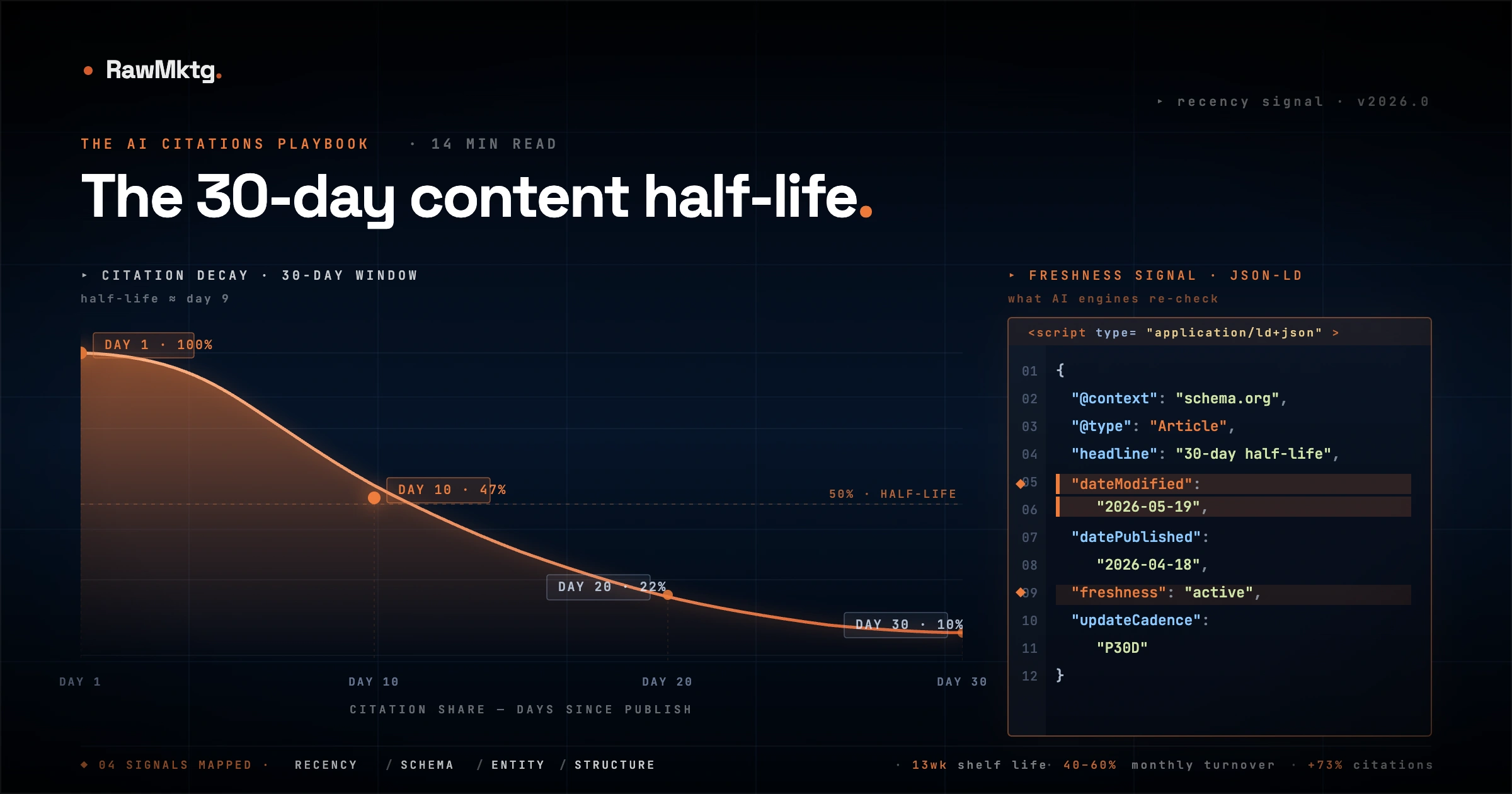
There is a number that should get every content strategist's attention: 3.2x.
That is how much more likely a page that has not been updated in 90 days is to completely lose its AI search citations compared to a page refreshed within the same window. This is the 30-day content half-life in action. And understanding it mechanically, not just philosophically, is the difference between a content program that compounds in value and one that quietly decays.
This article unpacks what is actually happening inside AI search engines, why recency has become a hard signal, how each major platform weighs freshness differently, and what a systematic refresh cadence looks like in practice.
Why is evergreen content losing its AI citations?
The shift is not simply that Google changed its algorithm. The deeper change is the rise of retrieval-augmented generation (RAG) as the architecture powering every major AI answer engine. RAG systems do not consult a cached index of historical rankings. Every time a query is processed, the engine runs parallel searches across real-time web content. Historical domain authority still provides a relevance signal, but it is filtered through a recency gate that older content increasingly fails to pass.
Traditional organic search traffic has always decayed, but slowly. Ahrefs data shows that most pages see gradual traffic declines over a 12-24 month horizon. AI citation loss operates on a categorically different timeline. Citation decay can begin within 30-45 days of a page going stale, and complete citation loss within 90 days is a documented pattern in fresh content tracking studies.
The brands winning in this environment understand something important: AI search does not reward authority the same way Google does. It rewards recent, structured, citable evidence. A well-structured page published last month can outperform an authoritative piece published two years ago, if the newer page contains fresh data, structured claims, and machine-readable formatting.
How fast do AI citations decay after 30 days?
This is not a bug. It is a feature of how RAG systems work. AI engines rely on live search grounding. Every time a query is processed, the engine runs fresh retrieval across the indexed web. A page that was well-positioned 90 days ago competes, in real time, against every page published or refreshed since then. If the older page contains stale data, outdated pricing, or superseded claims, the retrieval model's relevance scoring will begin to favour more recent alternatives.
Over 80% of citations answering commercial queries are pulled from pages updated within the prior 30 days. That number has held across multiple tracking studies spanning different query types and AI platforms. The 30-day window is not a rule imposed by any single platform. It is an emergent property of how retrieval systems score freshness signals across all major engines simultaneously.
Why is recency a hard ranking signal, not a preference?
Live Search Grounding and Inherited Freshness Bias
Large language models have a fixed training cutoff. To answer questions about the present, including current pricing, recent product updates, and current vendor comparisons, they rely on live web retrieval. The search grounding layer inherits the freshness scoring of the underlying search engine. When Google or Bing surfaces recent results as more relevant to a query, the AI's retrieval layer inherits that signal directly. Fresh content gets higher placement in the retrieved context window, which means it gets synthesised first and weighted more heavily in the final answer.
LLMs as Second-Stage Rerankers
Once retrieved documents land in the LLM's context window, the model acts as a second-stage reranker. Research into how LLMs handle date signals shows a consistent pattern: when two identical passages are compared, injecting a newer publication date reverses the model's preference in the majority of cases. The model treats recency as a proxy for reliability, particularly for factual claims about markets, pricing, and competitive landscapes.
This is not a bias that gets corrected over time. It reflects a rational strategy for a model trying to minimise hallucination risk. When uncertain between two sources, defaulting to the more recent one reduces the chance of citing a fact that has since been superseded.
The Query Fan-Out Amplifier
There is a third mechanism worth understanding: query fan-out. When a complex B2B query enters Google AI Mode or Perplexity, the system decomposes it into multiple sub-queries and runs them in parallel. A query like "best contract management software for mid-market" might fan out into sub-queries about pricing, integrations, compliance features, and recent user reviews simultaneously. Content that lacks machine-readable recency signals is structurally filtered out of these sub-queries during the initial retrieval pass, before any quality or relevance scoring happens.
How does each AI engine weigh content freshness?
| Platform | Recency Sensitivity | Top Citation Signals | Key Takeaway |
|---|---|---|---|
| ChatGPT | High (90-day window) | Pricing tables, comparison tables, scenario-based content | Structure wins. Narrative content without direct-answer formatting performs significantly worse. |
| Perplexity | Very High (near real-time) | Structured timestamps, updated statistics, visible date signals | Make freshness visible in code, not just prose. Perplexity reads and weights explicit date metadata. |
| Claude | Moderate (6-month window) | Long-form depth (2,000+ words), methodological transparency, citations | Substance over speed. One deep, well-cited source beats three thin, recent ones. |
| Google AI Overview | High + Schema-dependent | FAQPage schema (+53% lift), HowTo schema, dateModified in JSON-LD | 60% of AI Overview citations bypass top-20 organic rankings. Schema and structured data are the lever here. |
How does zero-click search change content ROI?
For CMOs managing blended customer acquisition costs, this matters concretely. Brands cited in AI answers see reduced CAC across paid and organic channels because AI citation presence functions as ambient credibility. Buyers arrive at a sales conversation having already encountered your brand framed as an authoritative source, which shortens evaluation cycles and improves close rates on inbound.
There is also a compounding multiplier between citations and mentions. Brands that secure both direct citations (where the AI cites your page as a source) and indirect mentions (where the AI references your brand name in an answer citing another source) benefit from a reinforcement effect. Buyers who encounter a brand name twice in AI answers, once as a citation and once as a reference, demonstrate meaningfully higher conversion intent than those who encounter it only once.
What does AI-ready content actually look like?
1. Logical Heading Hierarchies
A single H1 tag as the primary anchor, supported by clean, sequential H2-to-H3 hierarchies, yields meaningfully higher citation rates than pages with flat or inconsistent heading structure. Retrieval models use heading hierarchies to segment pages into coherent chunks during the indexing process. A disorganised heading structure creates chunks that lack standalone meaning, making them harder to retrieve for any single sub-query.
2. Direct Answer Boxes
Narrative introductions are a structural liability in AI search. Placing a concise direct answer box immediately below a section heading, before any supporting explanation, gives retrieval systems a clean, extractable response to a specific question. Pages that lead with the answer and follow with supporting evidence consistently outperform pages with the same information buried in narrative prose.
3. Entity Density
Retrieval systems rely on semantic entity mapping to determine contextual relevance. B2B content should target 8-12 recognisable entities per 1,000 words: named companies, product categories, regulatory frameworks, market metrics, and named methodologies. Entity-dense content clusters more tightly in vector space, which means it appears in more sub-query retrievals across a given query fan-out.
4. AI Learning Notes
A lightweight machine-readable summary annotation placed at the top of high-value pages, outlining the core entities covered, the key claims made, and the data sources referenced, provides a structured signal that retrieval models can read without needing to parse the full document. This is the content equivalent of a structured abstract in academic publishing.
5. Schema Markup
For Google AI Overviews specifically, structured JSON-LD schema is the highest-leverage technical investment available. FAQPage schema yields a documented 53% lift in AI Overview citation rates. HowTo schema and Article schema with populated dateModified fields provide the recency signals that Perplexity and ChatGPT's grounding layers weight heavily during retrieval scoring.
How often should you refresh content to keep AI citations?
The Four-Tier Prioritisation Model
| Tier | Content Type | Refresh Cycle | Why It Matters |
|---|---|---|---|
| Tier 1 | Revenue-adjacent pages (pricing, comparisons, use cases) | 8-12 weeks | Direct conversion risk if citations drop. These pages are actively consulted during vendor evaluation. |
| Tier 2 | Thought leadership and category authority content | 12-16 weeks | Anchors brand positioning in AI answers. Loss here reduces competitive presence in awareness-stage queries. |
| Tier 3 | Supporting informational content and FAQs | 6 months | Supports Tier 1 and 2 via entity coverage and internal linking density. |
| Tier 4 | Archive candidates | Evaluate for retirement | Consolidate or redirect. Do not invest refresh resources in pages with no pipeline value. |
The Five-Step Refresh Workflow
- Audit and inventory. Export the CMS library with organic traffic, last-modified dates, and existing schema types flagged. This is the master refresh queue.
- Prioritise by pipeline value. Revenue-adjacent pages get first priority. Citation loss on a Tier 1 page is a live conversion event, not just a visibility metric.
- Execute substantive updates, not cosmetic ones. AI models evaluate reasoning usefulness. They are not fooled by year-changing the title or reordering paragraphs. Refreshes must add new data points, updated statistics, new structured comparisons, or expanded schema.
- Deploy recency signals. Update the CMS modification date. Update the JSON-LD dateModified field. Add a visible "Updated: [Month Year]" annotation above the fold. These three signals together maximise retrieval-layer recency scoring across all major platforms.
- Track citation recovery. Monitor citation status across ChatGPT, Perplexity, and Google AI Overviews over a 4-6 week post-refresh window. Citation recovery timelines typically run 2-4 weeks for Perplexity, 4-6 weeks for ChatGPT, and 6-8 weeks for Google AI Overviews.
How do you measure AI citation performance?
The Core Query Set
Curate 20-30 queries that represent how your ICP actually searches when evaluating solutions in your category:
- Category queries (approx. 10): "Best [Category] platforms" or "What is [Category]"
- Problem queries (approx. 10): "How to [action your product enables]" or "Why does [problem] happen"
- Competitor queries (5-10): "[Competitor] alternatives" or "[Competitor] vs [Category]"
Run this query set every 3-5 days for priority terms, weekly or biweekly for the full portfolio, across ChatGPT, Perplexity, and Google AI Overviews.
The Three Core Metrics
| Metric | Definition | Intervention Threshold |
|---|---|---|
| AI Citation Rate (ACR) | Percentage of tracked queries where your domain is cited in any form. | Below 25% signals a structural problem with content accessibility or freshness across the portfolio. |
| Citation Retention Rate (CRR) | Percentage of citations that persist from one audit run to the next. | CRR below 60% is the primary early warning signal for content decay. Trigger a refresh audit immediately. |
| Share of Model (SOM) | Your citation count as a percentage of total citations across the tracked query set, including competitor citations. | Declining SOM with stable ACR indicates competitors are gaining ground faster than you. Increase refresh cadence on Tier 1 pages. |
Citation Readiness Scoring
| Score | Readiness Level | What to Do |
|---|---|---|
| 20-25 | High Readiness | Structured tables, strict heading hierarchy, direct-answer formatting throughout. Maintain refresh cadence. |
| 15-19 | Moderate Readiness | Accurate content but missing structured formatting or schema. Add direct-answer boxes and FAQ schema to prioritise pages. |
| 10-14 | Low Readiness | Long-form narrative structure without logical chunking. Restructure with heading hierarchy and extract key claims into direct-answer format. |
| Under 10 | Not Citation Ready | Subjective or narrative content lacking factual claims, data, or structure. Full rewrite or consolidation required before investing in refresh cadence. |
The 90-Day Operational Rollout Plan
Days 1-30: Make the domain maximally AI-accessible
Objective: make the existing domain maximally accessible to AI crawlers and establish a measurement baseline.
- Days 1-2: Verify robots.txt does not block GPTBot, PerplexityBot, or Google-Extended
- Days 3-10: Audit structured data gaps across high-traffic landing pages; deploy FAQPage schema on key service and support pages
- Days 11-15: Configure GA4 to track referral traffic from OpenAI, Perplexity, and generative sources
- Days 16-22: Rewrite introductory blocks of top-20 traffic posts to lead with direct, factual answers
- Days 23-26: Publish an llms.txt file, a markdown summary of the site's structure for machine-learning parsers
- Days 27-30: Run first manual audit of 20-30 core ICP queries to establish a performance baseline
Days 31-60: Execute substantive on-page updates
Objective: execute substantive on-page updates across high-priority content templates.
- Days 31-40: Re-optimise core solution pages with entity density and direct-answer formatting
- Days 41-45: Embed data visualisations, comparison tables, and visual process diagrams
- Days 46-52: Publish supporting informational sub-topics with clean internal linking to primary solution pages
- Days 53-57: Deploy structured Person and Author markup linking experts' bio pages to canonical social profiles
- Days 58-60: Mid-cycle citation check vs. Day 30 baseline; database updates take 4-8 weeks to propagate
Days 61-90+: Build off-site validation
Objective: build off-site validation and secure third-party brand mentions.
- Days 61-75: Secure placements on high-ranking external domains, industry listicles, and category roundups. These are the referring sources AI systems treat as corroborating signals.
- Days 76-85: Participate in Reddit and community forums with factual, helpful answers that feed the UGC layers used by AI systems for corroboration
- Days 86-90: Re-run core query set across ChatGPT, Perplexity, and Gemini; structure refresh queue for the next 90-day cycle
The Budget Model That Supports This Strategy
| Allocation | Category | Rationale |
|---|---|---|
| 0% | Commodity SEO articles | Generic guides are easily synthesised by AI. Publishing them adds volume but no citation value, and dilutes crawl budget. |
| 50% | Proprietary data journalism | Original research, surveys, and unique benchmarks create primary sources that AI systems cite because they contain information that cannot be synthesised from other sources. |
| 30% | Video atomisation and UGC | Short-form video and community content increases the total surface area where your brand and expertise appear across the non-traditional content layers that AI systems increasingly ingest. |
| 20% | Technical GEO infrastructure | Schema deployments, semantic markup audits, and structured data maintenance. This is the plumbing that enables everything else to work. |
Defending this to your CFO, three points:
First, AI citations directly protect paid advertising efficiency. Brands cited in AI Overviews earn a 35% increase in organic CTR and a documented reduction in cost-per-click on branded terms, because ambient AI citation presence pre-qualifies buyers before they reach paid search.
Second, traditional ranking is no longer a protective moat. Roughly 60% of AI Overview citations go to pages outside the top-20 organic results. The implication is that a brand ranked #1 in traditional search for a query is not guaranteed AI citation presence, while a brand ranked #25 with superior structure and freshness may appear in every AI answer for that query.
Third, AI-referred traffic converts at a higher rate. AI-referred sessions demonstrate meaningfully higher commercial intent than sessions from traditional organic search, because buyers using AI search are typically further along in their evaluation process and searching with more specific, decision-stage queries.
The Strategic Conclusion
The 30-day content half-life is not a temporary phenomenon that will correct itself as AI search matures. It is a structural feature of how retrieval-augmented generation works, baked into the architecture of every major platform.
The teams that adapt fastest are not the ones with the largest content libraries or the highest domain authority scores. They are the ones that treat content freshness as an operational system, with defined tiers, scheduled refresh cycles, measurable citation metrics, and a budget model aligned to where AI citation value actually accrues.
For content strategists, that means a systematic refresh calendar that keeps revenue-adjacent pages inside the citation window, a measurement framework built around AI Citation Rate and Citation Retention Rate, and a budget reallocation toward proprietary data and technical GEO infrastructure. In fast-moving categories, freshness becomes a moat: see how it reshuffles the AI presentation-tools race.
The search result page that buyers see is increasingly generated, not ranked. The brands that appear in those generated answers are the ones that will define category leadership over the next three to five years. The system to get there is manageable, measurable, and starts with a single refresh audit this week.
How often should content be updated to retain AI citations?
Pages updated within 30 days show the highest AI citation retention. Beyond 90 days, pages are 3.2x more likely to lose citations regardless of domain authority. Updating at least the dateModified schema value alongside substantive content changes is the most reliable way to stay inside the citation window.
Which AI platforms weight content recency most heavily?
Perplexity applies the tightest recency window at approximately 30 days. Google AI Overviews rely heavily on the dateModified schema signal. ChatGPT applies a roughly 90-day window, while Claude weights recency alongside factual precision. All four platforms deprioritise content beyond 90 days regardless of backlink profile.
What is the content half-life in AI search?
The content half-life is the decay curve of AI citation eligibility. Citation probability begins declining after 30 days without an update, drops sharply at 60 days, and reaches near-zero at 90 days. The primary signal AI engines use to measure freshness is the schema-declared dateModified field, not crawl date alone.
This article draws on research from: AirOps State of AI Search 2026, Presenceai Citation Rates Research, Knecht Strategy AI citation tracking study, and Ahrefs organic traffic decay data. Data reflects conditions as of Q1-Q2 2026.