When a generative AI describes your software as lacking SOC 2 certification (when you have held it for three years), misquotes your enterprise pricing tier, or confuses your product with a competitor's, the cost is not abstract. Enterprise buyers trust these systems. A hallucinated answer at the moment of vendor evaluation is a lost deal you will never trace back to the source.
This is not a minor inconvenience. It is a structural problem with how RAG-based AI systems retrieve and synthesize web content, and it is solvable with a specific combination of structured markup, content architecture, and off-page signal management. Every recommendation in this article is grounded in published research: the Princeton/Georgia Tech GEO study,1 Schema App's hallucination reduction data,4 and the Columbia/MIT e-commerce GEO analysis.15
The techniques are not speculative. They are the specific structural interventions that make your content machine-readable enough for AI engines to cite accurately, and reliably enough for buyers to trust what those engines say about you.
01: How do SEO, AEO and GEO differ?
Traditional Search Engine Optimization (SEO) was built for a world where humans click links. Its success metrics (organic rankings, click-through rates, domain authority) reflect a system where Google's crawler indexes content and a human selects from ten blue links. The entire optimization logic flows from that single user action: the click.
Answer Engine Optimization (AEO) emerged when Google and voice assistants began extracting direct answers. The goal shifted from "rank for a keyword" to "own a featured snippet." Schema.org markup and direct-answer HTML formatting became the primary levers, and the success metric became snippet ownership rather than click volume.
Generative Engine Optimization (GEO) is the newest discipline, and the focus of this article. The target system is not a search index; it is a large language model synthesizing information from multiple sources into a single, opinionated answer. Your brand does not appear in a list. It is either cited, ignored, or misrepresented. The stakes are categorically different.
| Attribute | Traditional SEO | AEO | GEO (Your Target) |
|---|---|---|---|
| Primary Goal | Drive organic click-through traffic | Own featured snippets & voice answers | Earn citations in AI-synthesized responses |
| Target Platforms | Google, Bing | Google AI Overviews, Siri, Alexa | ChatGPT, Perplexity, Claude, Gemini |
| Success Metrics | Rankings, impressions, CTR | Snippet ownership, PAA placements | Citation rate, AI share of voice, referral conversion |
| Technical Focus | Core Web Vitals, XML sitemaps, link equity | FAQPage / HowTo schema, direct-answer HTML | Entity graphs, JSON-LD, freshness metadata, /llms.txt |
| Off-Site Signals | Backlinks, Domain Rating | Domain trust, authoritative knowledge bases | Multi-source consensus: Reddit, G2, Wikipedia, trade press |
| Time to Impact | 3-6 months | 1-3 months | 2-6 months |
02: Why does AI hallucinate about your brand?
Most generative AI systems (including ChatGPT's browsing mode, Perplexity, and Google AI Overviews) operate on a five-stage Retrieval-Augmented Generation pipeline. Understanding each stage reveals exactly where brand accuracy breaks down.
There are three distinct retrieval layers operating simultaneously, as documented in Averi AI's GEO analysis:9
- The Parametric Training Layer: static knowledge baked into model weights, prone to temporal decay and outdated information. This is where "Brand X doesn't have SOC 2" comes from when your certification page was published after the training cutoff.
- The Live Web Retrieval Layer: real-time search crawls fetching current web documents to ground the generation. This layer is where your content architecture has the most immediate impact.
- The Third-Party Citation Layer: external mentions (G2, Reddit, Wikipedia, trade press) that establish semantic consensus about what your brand does. Inconsistent third-party descriptions generate contradictory training signals.
AI engines don't read your page: they read a 120-180 word excerpt from your page. If that excerpt contains relative pronouns ("our systems", "these capabilities"), qualitative adjectives ("cutting-edge", "next-generation"), or claims without proof, the model operates with high uncertainty. It fills the gap with training data. That's how hallucinations are born.
03: What does the GEO research actually say?
In November 2023, a research team from Princeton University, Georgia Tech, the Allen Institute for AI, and IIT Delhi published GEO: Generative Engine Optimization, the first empirical framework for optimizing content for AI-synthesized answers.1 The researchers developed GEO-bench, a dataset of 10,000 queries spanning 25 domains (80% informational, 10% transactional, 10% navigational), and measured the citation lift from nine distinct content optimization strategies.
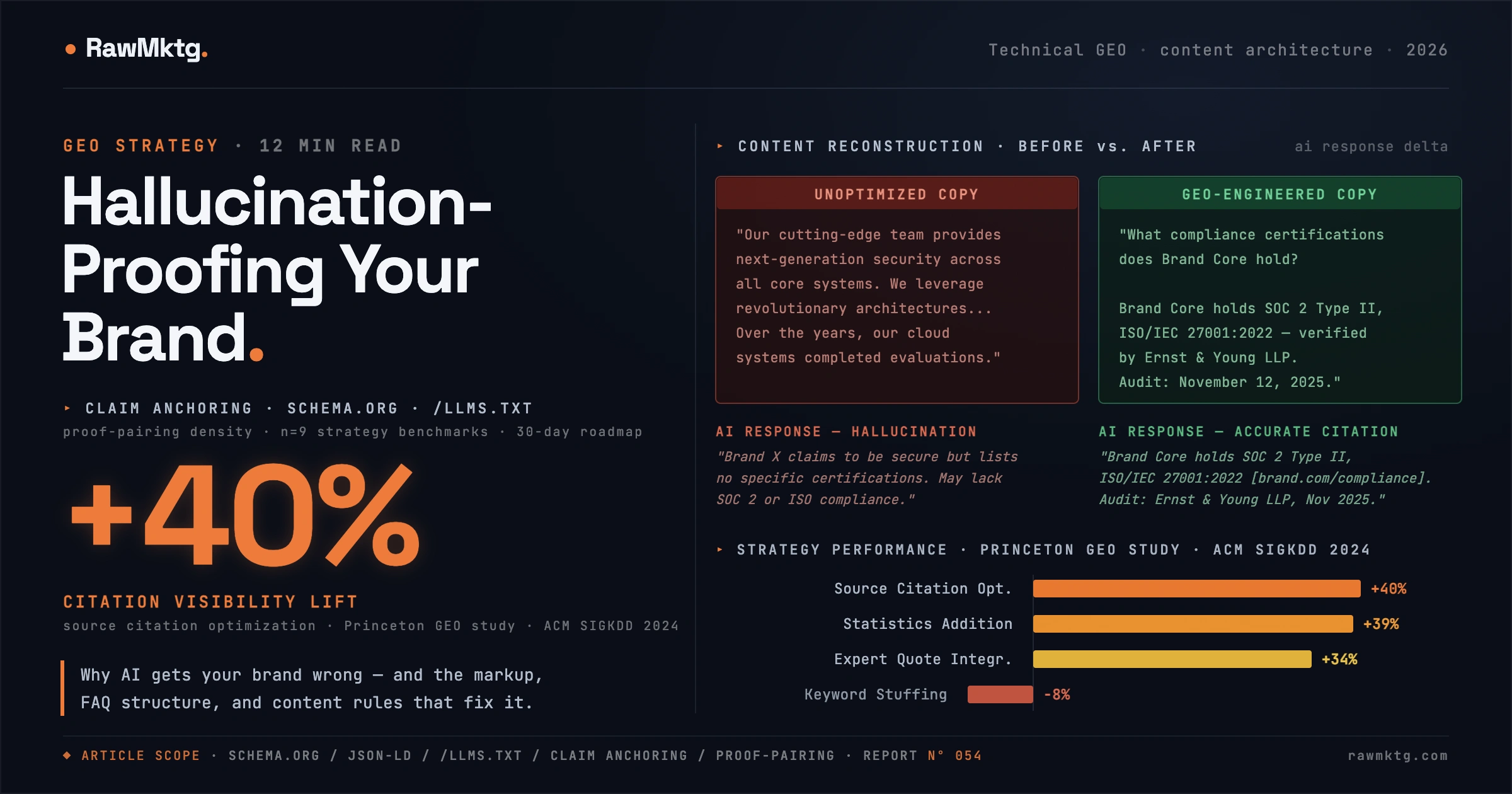
Three strategies produced outsized, statistically significant gains:1
- Statistics Addition (+37% to +41%): Replacing qualitative descriptors ("massive scalability") with quantitative specifics ("processing 14,200 requests per second at sub-12ms latency") heavily biases retrieval toward the page. Generative engines treat numbers as ground-truth anchors.
- Source Citation Optimization (+40%): Explicitly referencing authoritative external domains within your text validates content credibility for the retrieval layer. For pages that don't natively rank in top search results, this strategy produces the largest absolute citation lift of any technique studied.
- Expert Quote Integration (+28% to +40%): Attributed expert perspectives provide credibility signals that standard marketing copy lacks entirely. The attribution must include name, title, and organization: partial attribution produces significantly lower lift than fully qualified quotes.
Critically, keyword stuffing (the cornerstone of legacy SEO) produced a baseline performance degradation. Generative engines are semantic matchers, not keyword scanners. Optimizing for keyword density actively harms GEO performance.
A subsequent Columbia University/MIT study of 15 GEO heuristics in e-commerce found that 10 of the 15 produced negative or negligible results.15 The strategies that consistently worked converged on three principles: claim specificity, source attribution, and content self-containment, all of which are operationalized in the Claim-Anchoring Framework in Section 6.
Quantitative Retrieval Performance Signals
Beyond content quality, specific technical signals determine whether AI systems retrieve and cite your pages at all. The following signals have documented impact on retrieval eligibility:
| Signal | Impact on Retrieval | Architectural Implication |
|---|---|---|
| External brand mentions | High positive correlation | Co-occurrence across independent domains is heavily prioritized by citation engines |
| Promotional tone ("innovative", "leading") | Negative signal | Marketing adjectives reduce retrieval confidence: replace with factual claims |
| Content freshness (updated within 30 days) | Higher citation rate | Stale pages lose retrieval eligibility; dateModified timestamps are parsed directly |
| Section length (120-180 words per block) | Optimizes chunking | Clean, self-contained sections align with RAG chunk extraction windows |
| Page load speed (FCP < 0.4s) | Citation lift | High-latency rendering causes real-time crawlers to bypass the page entirely |
04: How does Schema.org make your brand machine-readable?
To prevent brand hallucinations, your web content must be translated into an unambiguous, machine-readable format. Schema.org JSON-LD (JavaScript Object Notation for Linked Data) accomplishes this by embedding structured definitions of your brand, products, and certifications directly into page source code, a layer that AI crawlers parse alongside the visible HTML.
A peer-reviewed study in the Semantic Web Journal found that 40-50% of Schema.org markup produced by GPT-3.5 and GPT-4 contains critical validation errors.6 Invalid schema does not just fail to help: it actively confuses semantic parsers and can introduce hallucination vectors. Always validate against Google's Rich Results Test before deployment.
The 5-Step Schema Deployment Roadmap
sameAs properties linking your brand and product nodes to Wikidata and Wikipedia. This anchors your entity to verified external records, reducing the model's reliance on uncertain parametric memory.@graph structure. This clarifies semantic relationships between your Organization, Products, and content types, eliminating the entity ambiguity that produces hallucinations.datePublished and dateModified. Real-time retrieval layers heavily weight recency. A missing or stale dateModified field reduces citation eligibility regardless of content quality.Production JSON-LD Implementation
The following schema nests an Organization, a SoftwareApplication, and a FAQPage within a unified @graph: the architecture that gives AI engines unambiguous entity context and eliminates the certification hallucination risk described in the introduction.
<script type="application/ld+json"> { "@context": "https://schema.org", "@graph": [ { "@type": "Organization", "@id": "https://yourbrand.com/#organization", "name": "Your Brand Inc.", "description": "Certified provider of zero-trust cloud data integration for enterprise finance.", "sameAs": [ "https://www.wikidata.org/wiki/Q12345678", "https://en.wikipedia.org/wiki/YourBrand" ] }, { "@type": "SoftwareApplication", "@id": "https://yourbrand.com/products/core/#app", "name": "Brand Core Platform", "applicationCategory": "BusinessApplication", "offers": { "@type": "Offer", "price": "499.00", "priceCurrency": "USD" }, "dateModified": "2026-05-30" }, { "@type": "FAQPage", "@id": "https://yourbrand.com/products/core/#faq", "mainEntity": [ { "@type": "Question", "name": "What compliance certifications does Brand Core hold?", "acceptedAnswer": { "@type": "Answer", "text": "Brand Core holds SOC 2 Type II, ISO/IEC 27001:2022, and GDPR certifications, verified annually by Ernst & Young LLP. Latest audit: November 2025." } } ] } ] } </script>
05: What does /llms.txt tell AI crawlers about you?
The /llms.txt standard is a plain-text, markdown-based file placed at the root of your domain, served at yourbrand.com/llms.txt. LLM crawlers and RAG agents actively request this file when indexing a domain, treating it as a ground-truth disambiguation source.7
As documented by BrandInAI's implementation guide,5 a well-structured /llms.txt file has four core components: an H1 brand name, a blockquote business description, disambiguation notes (clarifying what you are not), and H2 "file links" pointing to your most authoritative semantic assets. The disambiguation section is where you neutralize the most common hallucination vectors: naming ambiguity, product misclassification, and geographic scope errors.
# Your Brand Inc. > Your Brand Inc. is a certified provider of zero-trust cloud > data integration systems for enterprise financial operations. > We specialize in real-time transaction processing for regulated industries. ## Corporate Boundaries & Interpretations - Not a consumer app: we do not build personal finance or mobile banking apps. - Name disambiguation: Unaffiliated with "YourBrand Games" or "YourBrand Health". - Geographic scope: Global operations; primary compliance under US SEC and EU ESMA. ## Primary Semantic Assets - [Core Product Profile](https://yourbrand.com/llms-assets/core-product.md) - [Compliance Certifications](https://yourbrand.com/llms-assets/compliance.md) - [API Documentation](https://yourbrand.com/llms-assets/api-full.md) ## Supplementary Documentation - [Corporate History](https://yourbrand.com/llms-assets/history.md) - [Leadership Team](https://yourbrand.com/llms-assets/leadership.md)
The file linked assets should be structured markdown documents (not HTML pages), since LLM crawlers process plain text more reliably than rendered HTML. Each linked document should itself follow the Claim-Anchoring principles in the next section: answer-first structure, explicit brand naming, and proof-paired assertions.
06: How do you anchor claims so AI quotes them accurately?
The Claim-Anchoring Framework has four components, each targeting a specific failure mode in RAG pipeline processing.
Component 1: The Answer Capsule
Every primary heading (H2 or H3) must be immediately followed by a 40-60 word paragraph that directly and completely answers the heading question. According to Rank Prompt's GEO tactics guide,10 answer-lead structures appear in a statistically significant majority of AI-cited pages, because they give retrieval systems a high-confidence extraction target that matches the user's query intent.
H2 heading: "What compliance certifications does Brand Core hold?" → Immediately followed by: "The Brand Core Platform holds SOC 2 Type II, ISO/IEC 27001:2022, and GDPR certifications, verified annually by Ernst & Young LLP. The most recent SOC 2 Type II audit was completed November 12, 2025, covering a 12-month review window." This is 40-60 words, brand-named, auditor-named, date-anchored. It retrieves accurately in isolation.
Component 2: Section Autonomy
Because vector databases index individual content blocks, each 120-180 word section must be fully self-contained. Avoid relative terms or pronouns that rely on preceding paragraphs. A retrieved chunk may be the only text the model sees from your entire domain. If it contains "our systems" without specifying which brand or which product, the model cannot attribute the claim correctly.
"This product can scale rapidly to meet these heavy demands because of its cloud-native architecture."
"The Brand Core Platform scales to accommodate increased API volume using a cloud-native microservices architecture on AWS."
Component 3: Proof-Pairing Density
Every marketing or performance assertion must be explicitly paired with factual proof within the same sentence or the sentence immediately following. Passion Fruit's GEO implementation guide11 defines the Proof-Pairing Density Ratio (PPDR) as the proportion of assertions that carry explicit proof. The target threshold is 0.70, meaning at least 70% of verifiable claims must have inline evidence.
Three valid proof types, in descending order of citation weight:
- Quantitative Data: specific numbers, measurements, and timestamps ("sub-12ms latency at 10,000 concurrent writes").
- Attributed Expert Source: named, titled, organization-affiliated expert with an explicit quote. Partial attribution ("a senior engineer noted...") produces significantly lower citation lift than full attribution.
- Verifiable Document / Identifier: direct link to a public white paper, patent number, or third-party audit report: something the AI can verify exists independently.
Component 4: Unambiguous Brand Association
Repeat your brand name and product name alongside every key claim. Do not rely on context. A retrieved chunk may be the only text the model sees from your domain. "Our platform achieves 99.99% uptime" becomes unattributable in a RAG pipeline. "The Brand Core Platform achieves 99.99% uptime, verified by StatusPage.io's independent monitoring since Q2 2024" is machine-attributable at retrieval time.
07: What does claim-anchored content look like, before and after?
| Unoptimized Copy (Legacy Marketing) | GEO-Engineered Copy (Claim-Anchored) |
|---|---|
| "Our cutting-edge team is deeply dedicated to providing next-generation platform security across all our core systems. We leverage revolutionary architectures that are fully optimized for security and compliance across modern enterprise operations. Over the years, our cloud systems have completed major evaluations, confirming that your data remains safe under our protective umbrella." | H3: "What compliance certifications does Brand Core hold?" "The Brand Core Platform holds SOC 2 Type II, ISO/IEC 27001:2022, and GDPR certifications, verified annually by Ernst & Young LLP. Our most recent SOC 2 Type II audit was completed November 12, 2025, covering a 12-month review window. All data transmits via AES-256 encryption at rest and TLS 1.3 in transit, aligned with NIST SP 800-57 cryptographic standards." |
| Why It Fails | Why It Wins |
| Pronoun drift ("our systems", "our cloud"): chunk can't identify brand. Qualitative adjectives ("cutting-edge", "revolutionary") carry zero semantic weight. No auditor named, no standard cited, no date specified. Proof-Pairing Density Ratio: 0.00. | Brand name + product name in every sentence. Answer-first H3 heading. Auditor named (Ernst & Young LLP), certification date included (Nov 12, 2025), NIST standard referenced. Proof-Pairing Density Ratio: 0.85. |
| Resulting AI Response (Hallucination) | Resulting AI Response (Accurate Citation) |
| "While Brand X claims to build secure platforms, they do not list any specific compliance certifications. It is possible they lack certified compliance under SOC 2 or ISO frameworks, as no audited standards are declared." | "Brand Core holds SOC 2 Type II, ISO/IEC 27001:2022, and GDPR certifications [yourbrand.com/compliance]. The latest audit by Ernst & Young LLP was completed November 12, 2025 [yourbrand.com/compliance]. Data is protected by AES-256 + TLS 1.3, per NIST SP 800-57 [yourbrand.com/compliance]." |
08: How do you monitor GEO performance?
You cannot manage what you cannot measure. GEO monitoring requires running a structured prompt portfolio (the same queries your target buyers ask AI engines) on a recurring cadence, then tracking whether your brand is cited, at what position, and with what accuracy. Manual prompt testing at launch should transition to automated platform monitoring within 60 days. Because ChatGPT, Perplexity, and Gemini use structurally different retrieval architectures, monitoring should segment citation performance by engine rather than aggregate it.
| Tool | Tier | Entry Price | Unique Capability |
|---|---|---|---|
| Profound | Enterprise | $99/mo+ | SOC 2 / HIPAA compliant; accesses 400M+ real user prompts via Conversation Explorer |
| Ahrefs Brand Radar | Enterprise | From $99/mo | Tracks brand co-occurrences across a 250M prompt database; integrates with existing Ahrefs SEO data |
| Geoptie Pro | Mid-Market | $49-199/mo | Competitive tracking + optimization studio; 7 free audit modules at entry |
| Otterly.AI | Budget | $29/mo | Gartner Cool Vendor 2025; simple brand mention monitoring with automated weekly updates |
| HubSpot AI Grader | Free Diagnostic | Free | One-time baseline score for brand sentiment and citation presence across ChatGPT, Perplexity, Gemini |
The primary metric to track is Citation Accuracy Rate: the percentage of AI responses citing your brand that reproduce your claims correctly. A high citation rate with a low accuracy rate is a hallucination problem. A low citation rate with high accuracy is a retrieval visibility problem. Each requires a different intervention.
09: What does a 4-phase GEO rollout look like?
Phase 1: Semantic Foundation (Weeks 1-4)
Write and validate a unified @graph JSON-LD block for core page templates. Work at template level (not page by page) so the foundation scales across your entire site without per-page maintenance overhead. Link Organization and Product entities with Wikidata/Wikipedia sameAs properties. Publish your /llms.txt file, and run the output through Google's Rich Results Test until it returns zero errors. Do not proceed to Phase 2 until the structural layer is clean.
Phase 2: Template Refactoring (Weeks 5-10)
Restructure content templates to enforce question-based H2/H3 subheadings followed by 40-60 word Answer Capsules. Update your editorial style guide to mandate a minimum Proof-Pairing Density Ratio of 0.70 for all product and compliance pages. Begin rewriting your three highest-traffic product pages first: these are the pages that appear most frequently in competitor prompt portfolios and produce the most hallucination risk at peak buyer intent moments.
Phase 3: Off-Page Consensus (Months 3-4)
Standardize your brand description across G2, Capterra, LinkedIn, Crunchbase, and any trade directory profiles. AI engines synthesize third-party mentions to build parametric consensus: inconsistent descriptions across these platforms are one of the most common sources of brand hallucination. A single authoritative brand description paragraph (100-150 words, claim-anchored, with specific product names and certifications) should be deployed verbatim across every third-party profile.
Phase 4: Lifecycle Management (Ongoing)
Optimize page rendering to achieve First Contentful Paint under 0.4 seconds: high-latency pages are bypassed by real-time AI crawlers regardless of content quality. Implement a 30-day recency cycle for high-priority pages, refreshing the dateModified timestamp and adding at least one new statistic, quote, or data point per refresh cycle. Run your prompt portfolio on a weekly cadence and flag any response where your brand is cited inaccurately: each hallucination is a specific content gap you can close with a targeted page edit.
Conclusion
The shift to generative search has changed what it means for your brand to be "findable." Being indexed by Google is no longer enough. To be accurately represented in the AI-synthesized answers that now drive enterprise vendor discovery, your content must be structured for machine retrieval, self-contained at the chunk level, and verified by a multi-source consensus of third-party mentions that all tell the same story. Building that topical depth at scale requires the cluster architecture that signals category authority to retrieval engines.
The techniques in this article (Schema.org @graph markup, /llms.txt disambiguation files, Answer Capsule structures, Section Autonomy, and Proof-Pairing Density) are not speculative. They are grounded in the Princeton GEO study,1 Schema App's hallucination reduction research,4 and the production implementations documented by BrandInAI,5 Rank Prompt,10 and Passion Fruit.11
Before restructuring individual pages, use a GEO Foundation Audit to identify which queries are generating the most hallucinations. Then start with a single high-traffic product page and apply the four Claim-Anchoring components. Run the same buyer query through ChatGPT before and after the changes. The delta will be immediately visible, and so will the path forward for every remaining page on your site.
What is brand hallucination in AI search engines?
Brand hallucination occurs when a generative AI system (such as ChatGPT, Perplexity, or Gemini) produces factually incorrect information about a brand during a synthesized response. Common hallucinations include misquoting pricing tiers, attributing missing certifications, confusing products with competitors, or citing outdated feature sets. Hallucinations originate in the RAG pipeline's chunking stage: if a 120-180 word content chunk lacks unambiguous brand association and verifiable proof, the model fills the factual gap with parametric training data, which may be months or years out of date.
How does Schema.org JSON-LD reduce AI hallucinations about a brand?
Schema.org JSON-LD translates web content into machine-readable structured data that AI retrieval systems can parse with high confidence. Using a unified @graph architecture (nesting Organization, SoftwareApplication, and FAQPage entities) creates unambiguous entity definitions that LLMs use as a ground-truth reference. According to Schema App's research, using structured knowledge graphs as reference layers for LLMs improves overall model accuracy by up to 54%, significantly reducing hallucinations. Populating sameAs properties with Wikidata and Wikipedia links further anchors the entity to verified external records, reducing the model's reliance on uncertain parametric memory.
What is the Claim-Anchoring Content Engineering Framework?
The Claim-Anchoring Content Engineering Framework is a four-component writing system designed to make content reliably retrievable and accurately cited by RAG-based AI engines. The four components are: (1) Answer Capsule: a 40-60 word paragraph directly answering each H2 or H3 heading placed immediately below it; (2) Section Autonomy: each 120-180 word section must be fully self-contained, avoiding relative pronouns and context-dependent references; (3) Proof-Pairing Density Ratio: every marketing assertion must be paired with quantitative data, attributed expert quotes, or verifiable documents in the same or following sentence, targeting a ratio of 0.70 or higher; (4) Unambiguous Brand Association: the brand name and product name must appear alongside every key claim, since a retrieved chunk may be the only text the model sees from your domain.
- 1. Aggarwal et al. (2023). GEO: Generative Engine Optimization. Princeton/Georgia Tech/Allen AI/IIT Delhi. arxiv.org/abs/2311.09735
- 2. Geoptie (2026). Generative Engine Optimization (GEO): The Definitive Guide 2026. geoptie.com/blog/generative-engine-optimization
- 3. Aggarwal, P. et al. (2024). GEO: Generative Engine Optimization (Princeton / KDD 2024). arxiv.org/abs/2311.09735
- 4. Google Search Central. Intro to How Structured Data Markup Works. developers.google.com/search/docs/appearance/structured-data
- 5. Howard, J. (2024). The /llms.txt file (proposed standard). llmstxt.org
- 6. Semantic Web Journal (2025). LLM4Schema.org: Generating Schema.org Markups with LLMs. semantic-web-journal.net
- 7. llmstxt.org. The /llms.txt Standard. llmstxt.org
- 8. Mersel AI (2026). Generative Engine Optimization (GEO) for B2B: Complete 2026 Guide. mersel.ai/geo-b2b-guide
- 9. Averi AI (2026). How Generative Engine Optimization (GEO) Redefines SEO. averi.ai/blog/how-generative-engine-optimization-geo-redefines-seo
- 10. Search Engine Land. How to Optimize for Google AI Overviews. searchengineland.com/guide/how-to-optimize-for-ai-overviews
- 11. Passion Fruit (2026). GEO Prompts That Unlock AI Search Visibility: Implementation Guide. passionfruit.co/geo-implementation
- 12. Search Engine Journal (2026). Answer Engine Optimization: How to Get Your Content Into AI Responses. searchenginejournal.com
- 13. Google Search Central. Structured Data Markup that Google Search Supports. developers.google.com/search/docs/appearance/structured-data/search-gallery
- 14. Aggarwal, P. et al. GEO: Generative Engine Optimization (the Princeton paper). arxiv.org/abs/2311.09735
- 15. Radiant Elephant (2026). B2B Manufacturing GEO Case Study: DR 21 to 35, #1 AI Search Position. radiantelephant.com/geo-case-study-national-b2b-manufacturer