For twenty years the job was simple to describe even if it was hard to do: rank on the results page, earn the click. Search has quietly changed shape underneath that job. The interface is moving from Boolean lexical retrieval to neural generative synthesis, the model reads, decides, and writes one answer, and most of the time the user never sees a list of links at all.
That shift produced what analysts call the Great Decoupling: conversational search volume is climbing while referral traffic to the open web collapses. Roughly 58% of Google searches now end without a click, rising to 83% when AI Overviews fire and 93% inside AI Mode. With traditional search volume projected to fall about 25%, the place where your brand gets chosen is no longer the index. It is the model.
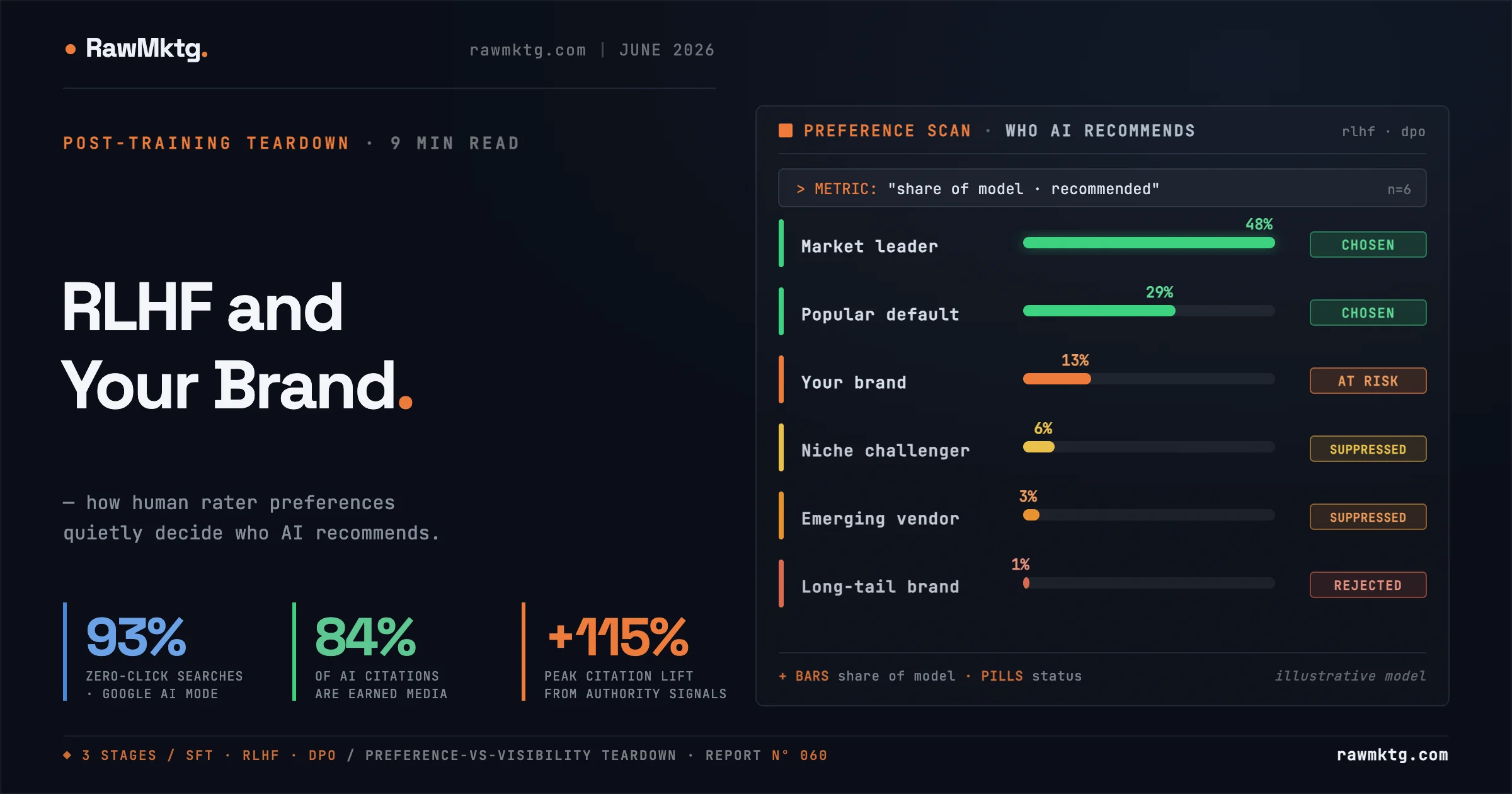
So the strategic question changes. It is no longer only how do I rank. It is what did the model learn to prefer, and how do I become the preferred answer? The answer lives in a layer most marketers have never audited: post-training alignment, Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO). It is now a brand-discovery channel.
01How does a model actually learn what to prefer?
Supervised fine-tuning sets the table
SFT trains the model on curated instruction-response pairs. It absorbs syntax, formatting, and the structural template of a helpful answer, but it cannot resolve subjective trade-offs between several plausible responses, and it is prone to confidently stating things that are not true. It teaches the model how to talk, not whom to trust.
RLHF and DPO set the preferences
RLHF collects human rankings of competing outputs, trains a separate reward model to predict the human-preferred score, then optimizes the model with PPO or GRPO, held in place by a KL-divergence penalty so it does not drift too far from the SFT baseline. DPO skips the reward model entirely, treating alignment as a binary classification problem: push up the probability of the chosen response, push down the rejected one. The catch marketers should circle: DPO has no concept of semantic equivalence. If your brand name appears as the chosen answer, the model learns your literal name, not a vendor like you.
# RLHF - maximize reward, but stay anchored to the SFT model
maximize E[ r(x, y) ] - B * KL( pi(y|x) || pi_ref(y|x) )
# ^ learned reward ^ regularizer, B ~ 0.1-0.5 (no policy collapse)
# DPO - same preference signal, expressed as one classification loss
L_DPO = -E[ log sigma( B*log pi(y_w|x)/pi_ref(y_w|x)
- B*log pi(y_l|x)/pi_ref(y_l|x) ) ]
# y_w = chosen -> your brand y_l = rejected -> the competitorNewer methods compress the pipeline further, ORPO folds SFT and alignment into one loss, and KTO drops pairwise rankings for simple good/bad labels, but the brand-relevant mechanic is constant: somewhere in training, a judge marked one answer better than another, and your brand was in one of those answers.
| Method | What it optimizes | Overhead | Brand-relevant risk |
|---|---|---|---|
| SFT | Cross-entropy on prompt-response pairs | Low | Teaches tone, not trust; can hallucinate |
| RLHF | Reward model + PPO/GRPO policy update | Very high | Controllable but unstable; reward hacking |
| DPO | Binary log-likelihood, chosen vs rejected | Moderate | Overfits literal tokens; no semantic equivalence |
| ORPO | SFT loss + odds-ratio penalty, unified | Low-moderate | Needs clean, contrastive preference signals |
| KTO | Utility loss on binary good/bad labels | Low | Robust to noisy labelers; needs more data |
02Why does AI preference harden into a moat?
Three forces stack. First, popularity-induced bias: historical brand dominance is baked into SFT data, and during alignment the optimizer overcorrects toward those popular associations, suppressing long-tail competitors to minimize entropy. Second, the self-consuming performative loop: as models generate the web's text, later models train on that synthetic output, amplifying their own biases and flattening conceptual diversity. Third, source bias: fine-tuning induces a measurable preference for low-perplexity, machine-clean text over equivalent human writing.
03Who did the model learn to believe?
Their instructions matter to you directly. OpenAI's Model Spec commands models to avoid sycophancy, hold an objective point of view, and express calibrated uncertainty, and raters are explicitly told to penalize models that agree with a user's misconceptions. The takeaway for brand teams is the opposite of legacy marketing instinct.
You cannot flatter, hype, or keyword-stuff your way into the answer. The model has been actively trained to resist persuasion and to reward claims that are verifiable, attributed, and externally corroborated. Trust is the ranking signal now, which is exactly why the next section is about evidence, not adjectives.
04What replaces ranking as the metric that matters?
Who actually gets cited? Muck Rack's May 2026 study of 25M citations found that earned media drives 84% of all generative AI citations, independent journalism makes up 27%, and paid or advertorial content is a rounding error at 0.3%. And the engines diverge sharply in how they cite.
Authority is also brutally concentrated: in Google AI Overviews, just three publishers capture nearly a third of all news citations, and the top ten take roughly 80%. Which means the comms desk, not the ad budget, holds the primary lever. And the structural moves that lift citation rates are now measured.
Coefficients are abstract until you point them at your own footprint. Toggle the levers below to model the lift on your brand's Share of Model. The math applies diminishing returns, because real-world signals do not stack cleanly.
Roughly how often you are cited in relevant AI answers today.
Modeled from the Princeton/KDD GEO coefficients, with diminishing returns on stacked signals (full weight on the strongest, then 70% and 50%). Directional, a planning aid, not a guarantee.
05What is the playbook to become the preferred answer?
Rebuild the content mix around novelty. Anchor on original signal, then amplify it. Hire a research analyst into the content team. Generalist copywriters cannot manufacture first-party data; an analyst running surveys and querying proprietary datasets ensures every asset introduces non-redundant Information Gain. Treat PR as a referencing engine. Because models favor third-party authority, earned placements seed the retrieval databases that LLMs draw from. Ship a brand hub with llms.txt. Hand crawlers a compressed map of your verified facts.
The llms.txt standard is a public Markdown file that points crawlers like GPTBot, ClaudeBot, and Google-Extended straight at your canonical facts, with llms-full.txt aggregating the deeper documentation. It is the cheapest high-leverage move on this list.
# Acme Robotics - llms.txt > Industrial inspection robots for regulated environments. ## Core Brand - [Brand Hub](https://acme.com/brand-hub): canonical facts, naming, positioning - [Product Specs](https://acme.com/specs): models, payloads, certifications ## Primary Research & Benchmarks - [2026 Field-Reliability Report](https://acme.com/research/2026): first-party, n=1,200 - [Implementation Framework](https://acme.com/framework): proprietary methodology ## Proof & Press - [Earned Media](https://acme.com/press): third-party coverage & citations
06Where does this leave marketing leaders?
CMOs who keep optimizing for density and page-rank are tuning an interface their customers are leaving. The durable position belongs to brands that understand the alignment layer, restructure content around genuine Information Gain, and earn the third-party authority that seeds every model's memory. Preference is being decided in training runs you will never see, but the signals it rewards are entirely within your control. Build the evidence, and become the answer.
What is RLHF, and why does it matter for marketing?
RLHF (Reinforcement Learning from Human Feedback) is a post-training stage where human raters rank a model's competing answers, a reward model learns to predict their preference, and the model is optimized toward it. For marketing it matters because this is where a model learns which sources and brands to prefer when it answers a question. If your brand was in the answers raters marked better, the model is more likely to recommend you, and that preference is decided in training, not at query time.
What is Share of Model?
Share of Model is the probability that your brand is selected as a grounding source when an AI model synthesizes its answer. As AI answers replace the ranked results page, Share of Model replaces rank position as the metric that matters. It is won through retrieval: the model vectorizes the query and a reranker scores candidate passages on factual density, contextual cohesion, and Information Gain, novelty that keyword-matched pages lack.
How do you increase your brand's Share of Model?
Build machine-readable authority around genuine Information Gain. Publish original first-party research and statistics, include attributed expert quotations, and earn third-party media (the source of 84% of AI citations). Princeton's GEO study measured the lift: high-authority outbound links add 40-115%, statistics 22-41%, and expert quotes 28-37%. Then ship an llms.txt so crawlers can find your canonical facts. You cannot hype or keyword-stuff your way in; raters trained the model to reward verifiable, corroborated claims.
- Princeton GEO: Generative Engine Optimization (KDD 2024)
- Muck Rack, What Is AI Reading? (25M citations, May 2026)
- OpenAI Model Spec
- Crackle PR, AI Search Runs on Earned Media
- Sundeep Teki, The Complete Guide to Post-Training LLMs
- Snorkel AI, LLM Alignment Techniques
- CausalDPO and the Self-Consuming Performative Loop (arXiv)
- The Smarketers, Information Gain: AI's Key SEO Metric
rawmktg. publishes data-driven teardowns of how AI search decides what to recommend, pulling AI-citation and SEO data to show where the visibility gaps are. Method: same data, same lens, every time. Contact: vinayak@rawmktg.com