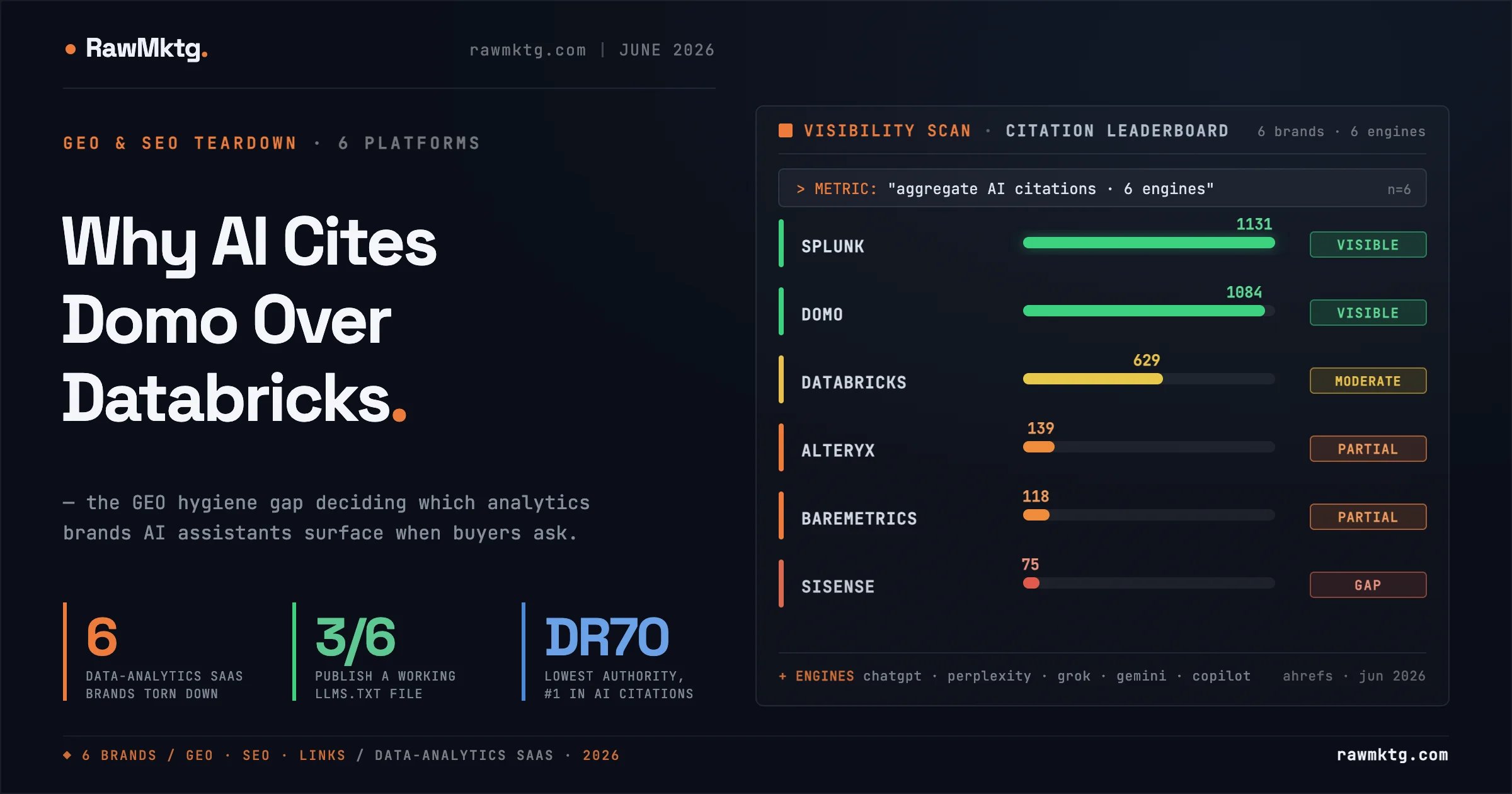
Six data-analytics platforms, the same six-stage visibility engine, and a result that should reset how you think about authority: Domo, the lowest-authority brand here at DR 70, posts the highest aggregate AI citations, out-citing DR-88 Databricks, which blocks crawlers at the access layer. Authority and AI visibility are correlated but not the same engine, and the gap between them is where the opportunity sits.
Domo, the lowest-DR brand (70), posts the highest aggregate AI citations. Databricks, the highest-traffic brand, under-converts. The cause is GEO hygiene, not authority, and it builds directly on the authority paradox we documented in proptech.
01How does the visibility engine work?
02What does the category scoreboard show?
| Company | DR | Traffic/mo | Value/mo | Ref dom | DR70+ | Spam | AI cites |
|---|---|---|---|---|---|---|---|
| Databricks | 88 | 1.3M | $2.3M | 31.9K | 2.8K | 24.8% | 629 |
| Splunk | 91 | 847K | $1.41M | 30.4K | 3.2K | 22.2% | 1,131 |
| Domo | 70 | 163K | $292K | 14.6K | 1.7K | 38.4% | 1,084 |
| Alteryx | 79 | 153K | $363K | 20.4K | 1.6K | 52.8% | 139 |
| Baremetrics | 77 | 34.8K | $31.2K | 4.2K | 605 | 23% | 118 |
| Sisense | 78 | 28.1K | $42.8K | 8.6K | 921 | 43.2% | 75 |
03The six engines, torn down
Databricks - Category Leader
The engine. A definitional-content flywheel on an enormous, clean backlink base, partly throttled by a hostile WAF.
| DR | Traffic/mo | Value/mo | AI cites | Branded | Spam |
|---|---|---|---|---|---|
| 88 | 1.3M | $2.3M | 629 | 58.6% | 24.8% |
Content engine. The deepest definitional library in the set. It owns the canonical 'what is X' queries (data warehouse, vector database, data lake) and pairs them with product-led pages. 41% non-branded across 31.2K keywords, 13.3K in the top three, the exact content shape AI engines summarize.
Link engine. 31.9K referring domains, 2,844 DR70+, at a clean 25% spam ratio. The differentiator is depth in developer ecosystems: GitHub links from over 2,000 pages, a co-citation moat no marketing campaign can fake.
GEO configuration. Strong on-page signals but two GEO holes: a WAF that returns 403 to non-browser agents on robots.txt and sitemap.xml, and no fetchable llms.txt. The result is an AI-citation share that under-indexes its traffic dominance.
| Keyword | Volume | Traffic | Pos |
|---|---|---|---|
| databricks | 485,660 | 455,720 | 1 |
| what is a data warehouse | 297,290 | 23,653 | 4.4 |
| what is a vector database | 320,000 | 19,228 | 4.2 |
| machine learning models | 161,610 | 20,221 | 2.6 |
| databricks careers | 20,350 | 16,947 | 1 |
What's working: Definitional 'what is' pages that map 1:1 to AI-answer queries; A developer co-citation moat (2,000+ GitHub linking pages); The largest, cleanest commercial footprint in the set.
Playbook, what to copy: Build a canonical 'what is X' library for every category concept; Pursue developer-ecosystem links for durable technical authority; Treat certification and community pages as link magnets.
Databricks taxes itself at the access layer. Where it blocks GPTBot/PerplexityBot and skips llms.txt, a fully-open competitor shipping FAQ schema over the same definitional terms can intercept the long-tail AI citations it leaves unconverted. Hard to beat on authority, easy to out-cite on hygiene.
Splunk - Authority Leader
The engine. A breadth-of-education content machine on the cleanest, highest-authority link base in the set.
| DR | Traffic/mo | Value/mo | AI cites | Branded | Spam |
|---|---|---|---|---|---|
| 91 | 847K | $1.41M | 1,131 | 43.5% | 22.2% |
Content engine. Publishes across the entire security and observability syllabus: risk frameworks, distributed systems, SIEM, hash functions. 56% non-branded, 38.4K keywords with 20.8K in positions 4-10, feeding a long tail of AI eligibility.
Link engine. The strongest profile here: ~30.4K referring domains, 3,193 DR70+, and the lowest spam exposure at 22%. Authority compounds because the profile stays clean.
GEO configuration. Technically the benchmark: valid robots.txt and sitemap, canonical, full Open Graph and Twitter, three JSON-LD blocks including VideoObject. Two blemishes: no llms.txt, and a templating bug leaking a broken hreflang token into the markup.
| Keyword | Volume | Traffic | Pos |
|---|---|---|---|
| splunk | 212,030 | 149,834 | 1.1 |
| risk management frameworks | 267,300 | 35,671 | 2.8 |
| software testing basics | 335,540 | 23,675 | 28.3 |
| what is a distributed system | 223,040 | 14,836 | 5 |
| hash functions | 165,490 | 10,876 | 5.4 |
What's working: Syllabus-wide content covering the whole category vocabulary; The cleanest link base in the set (22% spam); Benchmark technical hygiene.
Playbook, what to copy: Own the full category glossary, not just bottom-funnel pages; Protect link hygiene as a KPI; Add VideoObject and rich JSON-LD to multiply entity signals.
Splunk is hard to displace on authority; the opening is GEO hygiene. No llms.txt and no FAQ schema over a massive glossary. A challenger that wraps the same definitional content in FAQPage markup and ships llms.txt can win definitional citations before Splunk closes the gap.
Domo - GEO Overperformer
The engine. A disciplined GEO configuration that converts modest authority into category-leading AI citations.
| DR | Traffic/mo | Value/mo | AI cites | Branded | Spam |
|---|---|---|---|---|---|
| 70 | 163K | $292K | 1,084 | 31.3% | 38.4% |
Content engine. Markets directly at the AI-agent buyer ('Governed Data for AI Agents') and ranks across BI terms plus a quirky high-traffic cluster (strip chart). 69% non-branded with a strong 6.6K Top-3 footprint on 12.6K keywords.
Link engine. 14.6K referring domains, 1,686 DR70+, but a 38% spam ratio hinting at historic low-quality accumulation. Authority is the lowest here (DR 70), which makes its citation lead all the more notable.
GEO configuration. The reason it over-performs: the richest llms.txt in the set (16KB of curated description), which tracks with category-leading citations (432 Grok, 336 AI Overviews, 302 AI Mode). The irony is broken basic metadata: no canonical, no meta description, only og:type on the homepage, and a sitemap served as application/rss+xml.
| Keyword | Volume | Traffic | Pos |
|---|---|---|---|
| domo | 136,440 | 34,947 | 2.9 |
| domo ai | 51,860 | 9,527 | 2.5 |
| strip chart data | 26,000 | 5,816 | 1 |
| business intelligence tools | 261,090 | 2,233 | 4 |
| strip chart meaning | 41,350 | 5,478 | 1.3 |
What's working: The richest llms.txt in the set, the clearest cause of its over-performance; Buyer-aligned positioning (AI agents, BI category); A strong Top-3 footprint for a mid-authority domain.
Playbook, what to copy: Copy the llms.txt discipline, the single highest-ROI GEO move; Align positioning to the emerging buyer and build content around it; Use Domo as the internal case study: low DR, high citations.
Do not fight Domo on GEO mechanics; fight it on authority. With only DR 70 and 38% spam, a competitor with cleaner DR70+ links can out-rank it on commercial BI queries while matching its schema discipline. Its broken homepage metadata is a quick credibility wedge.
Alteryx - Branded-Dependent
The engine. A powerful brand-SERP harvester with almost no non-branded discovery engine behind it.
| DR | Traffic/mo | Value/mo | AI cites | Branded | Spam |
|---|---|---|---|---|---|
| 79 | 153K | $363K | 139 | 73.9% | 52.8% |
Content engine. 74% of traffic is branded (alteryx, certification, community, designer, download). The non-branded layer is thin and softening, a demand-harvesting engine, not a demand-generation one.
Link engine. Second-largest footprint (20.4K referring domains, 1,555 DR70+) but the worst spam exposure in the set at 53%; more than half its referring domains add risk rather than authority. A disavow program is overdue.
GEO configuration. WordPress with full Open Graph and clean headings, but two faults: no llms.txt, and the conventional /sitemap.xml returns 404 (the real index hides at /sitemap_index.xml), so crawlers probing standard paths can miss it.
| Keyword | Volume | Traffic | Pos |
|---|---|---|---|
| alteryx | 94,720 | 75,390 | 1.2 |
| alteryx certification | 3,910 | 3,588 | 1 |
| alteryx community | 2,900 | 2,638 | 1 |
| trifacta | 2,080 | 1,706 | 1.2 |
| alteryx designer | 2,780 | 1,589 | 1.1 |
What's working: Total ownership of its brand SERP; Healthy traffic value ($363K/mo) and full Open Graph; A large raw link footprint to build on once cleaned.
Playbook, what to copy: Treat brand-SERP completeness as table stakes, then layer non-branded content; Use full Open Graph everywhere for rich entity signals.
Alteryx is wide open on non-branded discovery. A competitor publishing strong how-to and comparison content for analytics-automation queries intercepts buyers Alteryx never reaches. Combine that with 53% spam and a missing/locked sitemap, and it is the most structurally exposed enterprise brand in the set.
Baremetrics - Niche Content Specialist
The engine. A pure editorial content engine that ranks enormous finance terms but lacks the authority to fully cash them in.
| DR | Traffic/mo | Value/mo | AI cites | Branded | Spam |
|---|---|---|---|---|---|
| 77 | 34.8K | $31.2K | 118 | 4.6% | 23% |
Content engine. The most content-led model here: 95% non-branded. It ranks for genuinely huge educational terms (churn rate analysis at 263K, what is a burn rate at 180K, MRR, cohort analysis). Editorial depth is real and category-relevant.
Link engine. The smallest authority base: DR 77 but only 4.2K referring domains, 605 DR70+, at a clean 23% spam. Stripe, Shopify and Medium links lend ecosystem relevance, but the base is too thin to lift it past more authoritative sources.
GEO configuration. Clean foundations: valid llms.txt, sitemap, canonical, and JSON-LD including SoftwareApplication. The gap is a missing og:image, so widely-shared finance guides render without a preview card, suppressing the social amplification that builds AI authority.
| Keyword | Volume | Traffic | Pos |
|---|---|---|---|
| churn rate analysis | 263,200 | 10,392 | 4.3 |
| what is a burn rate | 180,200 | 4,856 | 10.4 |
| baremetrics | 1,290 | 1,357 | 1 |
| startup financial modeling | 38,000 | 742 | 12 |
| mrr | 37,930 | 444 | 8.8 |
What's working: The purest content engine: ranks 263K-volume terms on a tiny domain; A clean technical base with llms.txt and commerce schema; Topically relevant ecosystem links (Stripe, Shopify).
Playbook, what to copy: Target enormous-volume educational terms adjacent to the product; Add FAQ/HowTo schema to calculators and guides; Earn topically-relevant ecosystem links, not just high-DR links.
Baremetrics wins on editorial depth and loses on authority. A competitor with more DR70+ links can out-rank its finance guides on the exact high-volume terms it depends on. Its missing og:image is a free amplification gap to exploit.
Sisense - Contracting Challenger
The engine. A decent SQL-tutorial niche engine that is actively decaying because its crawl infrastructure is broken.
| DR | Traffic/mo | Value/mo | AI cites | Branded | Spam |
|---|---|---|---|---|---|
| 78 | 28.1K | $42.8K | 75 | 28.5% | 43.2% |
Content engine. Owns a focused SQL-tutorial niche (order of execution in sql, group by in sql, python data analysis) with a 72% non-branded mix. But the footprint is shrinking to just 2.1K keywords, the smallest active library in the set, and traffic is contracting.
Link engine. 8.6K referring domains, 921 DR70+, but a 43% spam ratio (second-worst). DR 78 is respectable; the problem is decay, not raw authority.
GEO configuration. Has an llms.txt, but the rest of discovery is broken: /sitemap.xml returns a 301 to an empty 0-byte response, and there is no hreflang. Crawlers cannot enumerate the site, the mechanical reason the keyword footprint is collapsing.
| Keyword | Volume | Traffic | Pos |
|---|---|---|---|
| sisense | 9,730 | 6,944 | 1.1 |
| order of execution in sql | 2,880 | 1,820 | 1.5 |
| python data analysis | 92,100 | 1,051 | 13.3 |
| group by in sql | 12,390 | 616 | 5.1 |
| mtd full form | 8,340 | 814 | 1.3 |
What's working: A focused SQL-tutorial niche with a good non-branded mix; A respectable DR 78 to rebuild from; It has published an llms.txt.
Playbook, what to copy: Even a struggling brand should ship llms.txt, discovery hygiene is cheap insurance; Defend a focused niche rather than spreading thin.
Sisense is the most beatable peer: a declining curve plus a broken sitemap means crawlers cannot index it properly. Consistent publishing on a working crawl stack would overtake it on embedded-analytics queries within two quarters, the lowest-effort share grab in the set.
04What do the cross-cutting patterns reveal?
Two opposite strategies bracket the set. Alteryx (74% branded) harvests existing demand; Baremetrics (95% non-branded) generates demand but cannot fully cash it without authority. The GEO-optimal middle is the definitional libraries of Splunk and Databricks. Nobody has yet layered FAQPage schema over those glossaries, the single softest spot in the category.
| Element | Databricks | Splunk | Domo | Alteryx | Baremetrics | Sisense |
|---|---|---|---|---|---|---|
| llms.txt | N | N | Y | N | Y | Y |
| Valid sitemap.xml | ~ | Y | Y | ~ | Y | N |
| AI-crawler access | N | Y | Y | Y | Y | Y |
| JSON-LD schema | Y | Y | Y | Y | Y | Y |
| Full Open Graph | Y | Y | N | Y | ~ | Y |
| Canonical tag | Y | Y | N | Y | Y | Y |
| hreflang | ~ | ~ | Y | Y | Y | N |
| Meta description | Y | Y | N | Y | Y | Y |
Legend: Y implemented, ~ partial or misconfigured, N missing or blocked. The three highest-leverage fixes across the set: add a canonical and meta description (Domo), allowlist AI crawlers at the WAF (Databricks), and wrap glossaries in FAQPage schema (everyone).
<!-- 1. Canonical (Domo) -->
<link rel="canonical" href="https://www.example.com/" />
<!-- 2. AI-crawler allowlist in robots.txt (Databricks) -->
User-agent: GPTBot
Allow: /
User-agent: PerplexityBot
Allow: /
<!-- 3. FAQPage schema over glossary (everyone) -->
<script type="application/ld+json">{"@context":"https://schema.org",
"@type":"FAQPage","mainEntity":[{"@type":"Question", ... }]}</script>05What's the synthesized playbook?
| Play | Why it works | Effort |
|---|---|---|
| Ship a rich llms.txt | Half the market has none; Domo proves it converts authority into citations | ~2h |
| Wrap glossaries in FAQPage schema | No one has done it; it is what engines extract for 'what is' answers | ~3h |
| Build a definitional 'what is X' library | Maps 1:1 to AI-answer queries; Splunk and Databricks win this way | Ongoing |
| Allowlist GPTBot / PerplexityBot | Crawler blocking silently caps citation eligibility | ~3h |
| Fix canonical + meta + Open Graph | Cheap entity-signal hygiene | ~2h |
| Pursue developer-ecosystem links | GitHub/docs co-citation is a durable technical-trust moat | Ongoing |
| Guard link hygiene as a KPI | Clean profiles compound; 22% beats 53% over time | Quarterly |
| Track AI share-of-voice separately from rankings | Authority and citation share diverge | Monthly |
# <Company> - <one-line positioning> > A concise description of what the company does and who it serves. ## Products - [Platform](https://example.com/product): overview and core capabilities ## Learn - [Glossary](https://example.com/glossary): definitions engines can quote - [Guides](https://example.com/guides): how-to content for category queries
06Where's the fastest share? (the attack plan)
| Target | Exposed weakness | The move | Ease |
|---|---|---|---|
| Sisense | Broken sitemap, contracting 2.1K-keyword footprint, 43% spam | Publish consistently on a working crawl stack; target SQL/embedded-analytics queries | Easiest |
| Alteryx | 74% branded, no llms.txt, sitemap 404s, 53% spam | Own non-branded analytics-automation how-to and comparison content | Easy |
| Baremetrics | Smallest authority base; missing og:image | Out-authority it on the high-volume finance terms it ranks | Moderate |
| Domo | DR 70 (lowest), 38% spam, broken homepage metadata | Out-rank on commercial BI queries with cleaner DR70+ links | Moderate |
| Splunk | No llms.txt, no FAQ schema, broken hreflang | Win definitional security citations with FAQ content + llms.txt | Hard |
| Databricks | WAF blocks crawlers; no llms.txt; under-converts | Be fully crawler-open and FAQ-structured to capture long-tail citations | Hard |
Easiest share: Sisense (broken sitemap, contracting) and Alteryx (74% branded, dirtiest links, no llms.txt).
Hardest to displace: Databricks and Splunk on authority, but both wide open on GEO hygiene.
The universal opening: nobody pairs a definitional glossary with FAQPage schema and llms.txt. That combination is unclaimed, and non-branded definitional content plus flawless crawl infrastructure beats raw authority for AI citations.
Why does Domo out-cite Databricks despite far lower authority?
Because AI citation is gated by GEO hygiene, not just Domain Rating. Domo publishes the richest llms.txt in the set (16KB) and markets directly at the AI-agent buyer, while Databricks blocks simple crawlers at its WAF and ships no fetchable llms.txt. Domo (DR 70) posts 1,084 aggregate AI citations versus Databricks' 629 (DR 88), because access and discovery gate everything above them.
What is the single highest-ROI GEO move for a data-analytics brand?
Ship a rich llms.txt. Only three of the six brands publish one, and Domo's detailed file tracks directly with its citation lead. It is roughly two hours of work and converts existing authority into citations, especially for mid-authority domains that can't win on Domain Rating alone.
Which brand is the most exposed to competitive attack?
Sisense. Its /sitemap.xml returns a 301 to an empty response so crawlers can't enumerate the site, its keyword footprint is contracting to 2.1K terms, and 43% of its referring domains are spam. Consistent publishing on a working crawl stack could overtake it on embedded-analytics queries within one to two quarters.
What's the unclaimed opportunity across the whole category?
Pairing a definitional 'what is X' glossary with FAQPage schema and a working llms.txt. The leaders (Splunk, Databricks) own the definitional content but have no FAQ schema or llms.txt; the GEO-disciplined brands (Domo) lack the authority. No one has combined all three, so non-branded definitional content plus flawless crawl infrastructure is the fastest path to AI citations.
rawmktg. publishes data-driven teardowns of B2B verticals and brands, pulling AI-citation and SEO data to show exactly where the visibility gaps are. Method: same data, same lens, every time. Contact: vinayak@rawmktg.com
Data source: Ahrefs (organic keywords, referring domains, Brand Radar AI citations) plus a live technical crawl of all six domains, captured June 2026.